MagiAttention#
A Distributed Attention Towards Linear Scalability for Ultra-Long Context, Heterogeneous Mask Training
Overview#
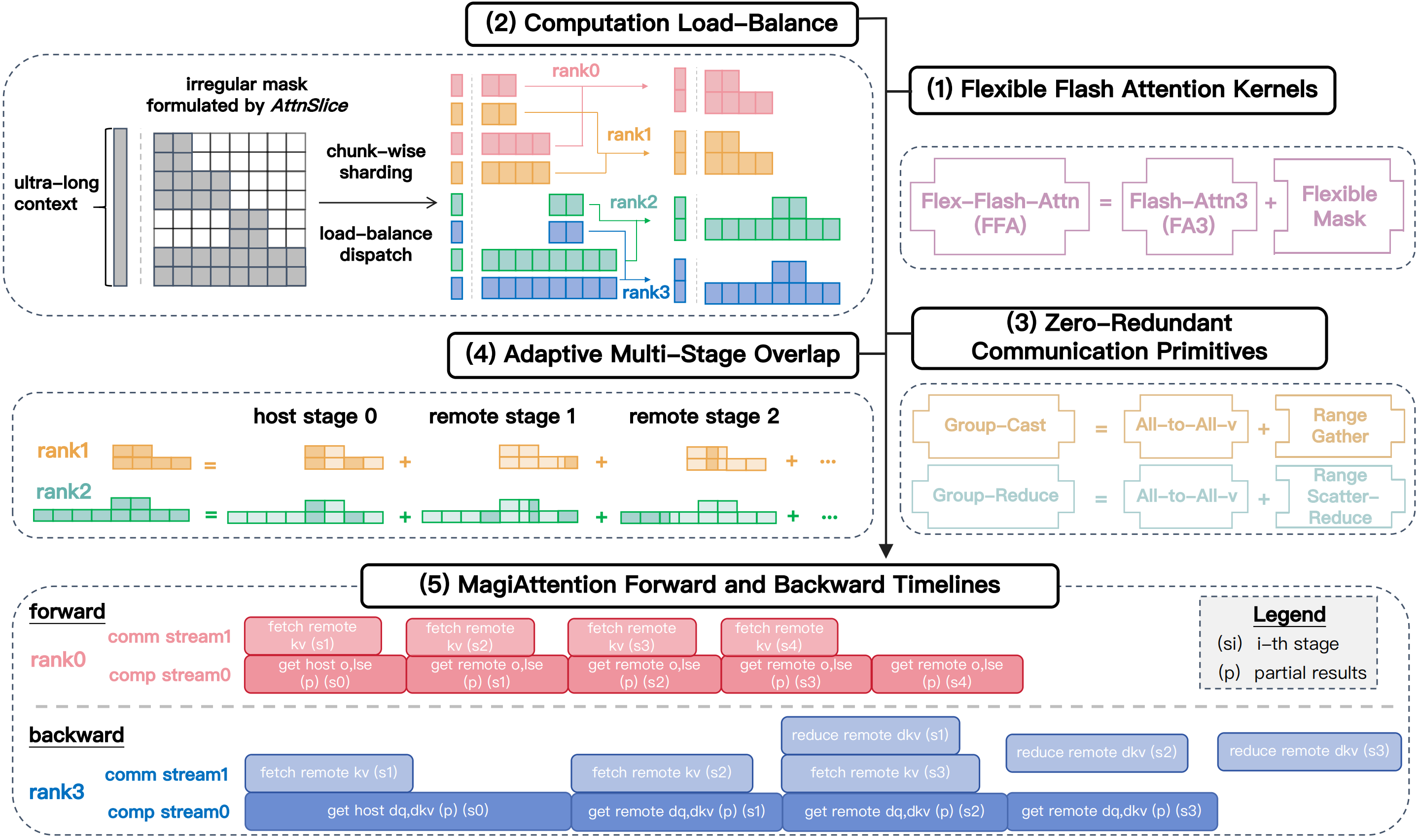
Fig. 1 Overview of MagiAttention: (1) FFA - an optimized kernel based on Flash-Attention 3, further supports flexible mask patterns; (2) The dispatch solver shards ultra‑long data and dispatches for load-balanced computation; (3) GroupCast and GroupReduce primitives eliminate redundant communication; (4) The overlap solver adaptively partitons multi-stage computation/communication for optimal overlap; (5) Forward and backward timelines scheduled by MagiAttention. With all components together, MagiAttention enables linear scalability in training with ultra‑long contexts and heterogeneous masks.#
Training large-scale video‑generation models faces two tightly coupled challenges: (1) ultra‑long contexts—reaching millions of tokens (e.g., ~4M)—which make attention prohibitively expensive in compute and memory, and (2) highly heterogeneous, irregular attention masks (e.g., block‑causal + Patch‑and‑Pack) that break assumptions of existing kernels and distributed layouts, leading to fragmentation, load imbalance, wasted padding, and large communication overhead.
These same constraints also affect (multimodal) LLMs that aim to support ultra‑long histories and flexible masking for agentic tasks with large retrievals and deep reasoning. Therefore, we require an efficient, mask-flexible, and scalable distributed attention solution.
To address these challenges, we propose MagiAttention, which targets these bottlenecks with kernel-level flexibility, while achieving distributed-level linear scalability across a broad range of training scenarios, particularly for those involving ultra-long contexts and heterogeneous masks like Magi-1.
Introduction#
Training large-scale autoregressive diffusion models for video generation (e.g., Magi-1) creates two tightly coupled system challenges. First, training contexts can reach millions of tokens, so naive quadratic attention or inadequately sharded algorithms quickly become infeasible in both compute and memory. Second, practical data pipelines—for example, block‑causal attention combined with Patch‑and‑Pack (PnP) processing [Dehghani et al., 2023] — produce highly heterogeneous, irregular masks and variable sequence lengths that violate assumptions made by standard attention kernels and distributed layouts. The combined effect is severe fragmentation, imbalanced compute across ranks, excessive padding, and large, often redundant, communication volumes.
Prior context‑parallel solutions [Chen et al., 2024, Fang and Zhao, 2024, Gu et al., 2024, Jacobs et al., 2023, Liu et al., 2023] partially mitigate these issues but introduce new limitations: head‑sharded designs impose divisibility constraints and reduce flexibility, ring‑style P2P schemes scale but incur large communication and redundancy under sparse/varlen masks. While recent efforts [Ge et al., 2025, Wang et al., 2024, Zhang et al., 2024, NVIDIA, 2025] dynamically adjust CP sizes to avoid unnecessary sharding and redundant communication for shorter sequences, they still incur extra memory overhead for NCCL buffers and involve complex scheduling to balance loads and synchronize across different subsets of ranks.
Crucially, existing methods do not simultaneously (1) provide a unified, distributable representation for a wide class of mask patterns, (2) guarantee balanced compute across context‑parallel (CP) ranks for arbitrarily structured masks, and (3) eliminate unnecessary data movement while enabling robust compute/communication overlap.
MagiAttention addresses these gaps by prioritizing kernel‑level flexibility together with distributed-level scalability, which depends on meeting the following fundamental conditions:
Linearly Scalable Attention Kernel: The performance of the attention kernel should not degrade as CP size increases. To this end, we introduce Flex-Flash-Attention, an extension of FlashAttention-3 (FA3), which natively considers the efficiency impact of attention mask partitioning in distributed environments. It supports distributable mask representations with a tailored kernel implementation to ensure scalability while accommodating a broader range of attention mask types.
Balanced Computational Workloads: Imbalances in the computational load across CP ranks lead to unavoidable idle bubbles that hinder scalability. MagiAttention is natively designed to ensure Computation Load Balancing, mitigating such inefficiencies.
Full Overlap of Communication and Computation: Without sufficient overlap, increasing CP size results in communication-induced idle time on GPUs, impairing scalability. MagiAttention introduces novel Zero-Redundant Communication Primitives to minimize communication overhead, along with an Adaptive Multi-Stage Overlap strategy that enables effective communication-computation overlap.
By coordinating a mask‑flexible kernel, a load‑balancing dispatcher, and zero‑redundancy communication with adaptive overlap, MagiAttention supports a broad spectrum of attention patterns while delivering distributed-level linear scalability across realistic ultra‑long and heterogeneous training workloads.
Below, we briefly review current CP strategies in Related Work, present the key designs in Methodology, and report comprehensive experimental results that validate the approach in Experiments.
We further elaborate upon preliminaries, extended functionalities, optimization techniques, and next-generation design in Miscellaneous, followed by the Future Work section. Our evolving exploration seeks to broaden the scope and redefine the frontiers of distributed attention, optimizing its performance for large-scale model training and extending its efficacy to inference scenarios in the future.
Related Work#
To handle ultra‑long contexts, context parallelism (CP) is essential, but existing CP strategies do not meet the real-world demanding settings.
DeepSpeed’s Ulysses [Jacobs et al., 2023] uses head-sharded attention with All-to-All transforms; it is easy to integrate but requires the number of heads to be divisible by the CP size, limiting scalability (e.g., GQA and when combined with head-aware tensor parallelism) [Korthikanti et al., 2022, Shoeybi et al., 2020].
Ring-Attention [Li et al., 2021, Liu et al., 2023, Wang et al., 2024] keeps sequence-sharded activations and relies on multi-stage ring-style P2P communication for online attention and overlap [Dao et al., 2022, Rabe and Staats, 2021, Wang et al., 2022]. It scales better than head-sharding but incurs large communication volumes and inefficient P2P primitives as CP size grows. Hybrid 2D schemes like USP [Fang and Zhao, 2024] and LoongTrain [Chen et al., 2024, Gu et al., 2024] combine Ulysses and Ring-Attention to reduce their weaknesses but still lack the fundamental efficiency and scalability needed for ultra‑long contexts.
Irregular masks (e.g., varlen) worsen these issues (see Fig. 2 below). Naive sequential even sharding creates uneven mask-area distribution and imbalanced compute across ranks. Custom zigzag sharding [zhuzilin, 2024] can rebalance specific varlen causal patterns but causes fragmentation, excessive padding, and kernel slowdowns, and it does not generalize to patterns such as the varlen block-causal mask used in autoregressive video generation for Magi-1.
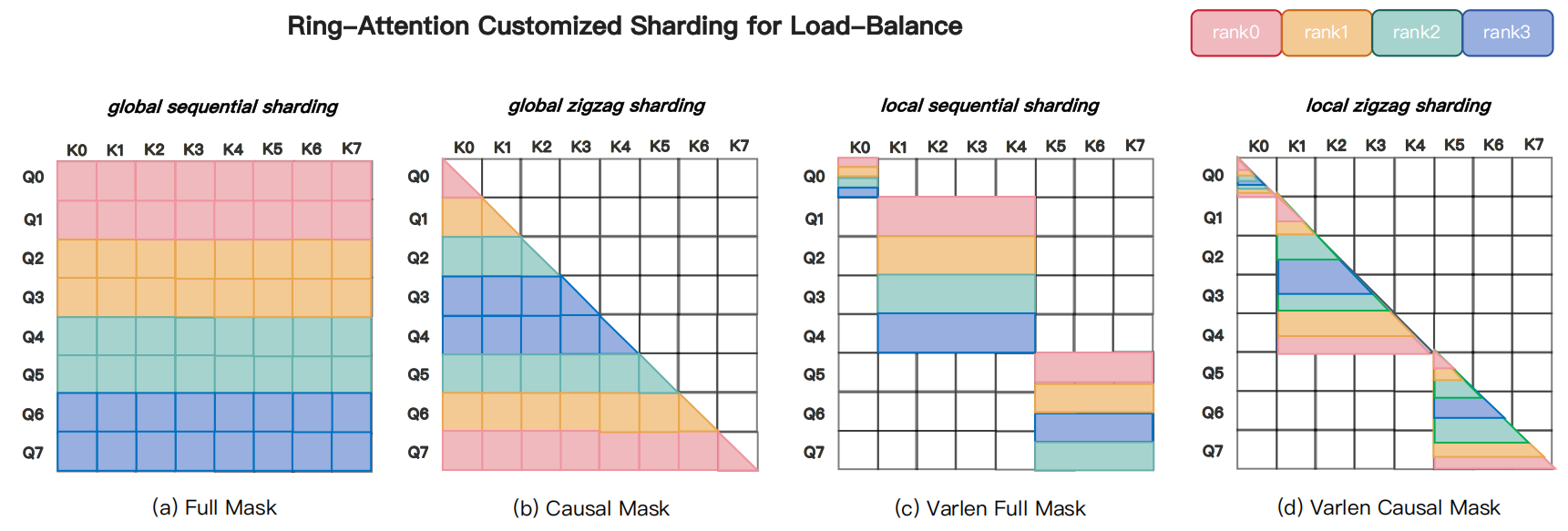
Fig. 2 Illustration of Ring-Attention’s sharding strategies for load balancing: (a) full mask — sequential sharding across the global mask; (b) causal mask — tailored zigzag sharding [zhuzilin, 2024]; (c) varlen full mask — sequential sharding per packed sample; (d) varlen causal mask — per-sample zigzag sharding, which increases fragmentation and padding and degrades performance.#
Second, communication overhead worsens under sparse varlen masks because entire sequence chunks are transferred to all CP ranks—even when many ranks do not need them—yielding over 30% redundant communication, as shown in Zero-Redundant Communication Primitives. Third, these inefficiencies undermine pipeline compute–communication overlap: imbalanced workloads and excessive communication make overlap fragile and constrain scalability.
Recent efforts like DCP [Ge et al., 2025, Wang et al., 2024, Zhang et al., 2024] and Hybrid-CP [NVIDIA, 2025] reduce redundant sharding by dynamically assigning CP group sizes per sample based on sequence length. However, they introduce significant scheduling complexity, frequent cross-group synchronization, and extra NCCL buffer memory, lacking of a bottom-up redesign required for robust, mask-flexible, and scalable distributed attention.
Methodology#
Flex-Flash-Attention#
AttnSlice Representation#
Flash-Attention [Dao, 2023, Dao et al., 2025, Dao et al., 2022, Shah et al., 2024] delivers high throughput, memory efficiency, and native support for varlen-packed inputs, making it a cornerstone for large-scale training. However, its kernels assume regular mask structure and do not handle irregular, rank-distributed masks efficiently—causing fragmentation, load imbalance, excess padding, and higher communication—so a mask‑flexible kernel that preserves Flash‑Attention’s performance is required [Dong et al., 2024, PyTorch, n.d., Wang et al., 2025].
Therefore, we introduce Flex-Flash-Attention (FFA), a kernel designed for distributed settings that flexibly handles diverse attention masks. FFA adopts a distributable representation that decomposes an irregular mask into multiple computational units called \(\mathrm{AttnSlice}\). Each \(\mathrm{AttnSlice}\) is the triplet \(\mathrm{(QRange, KRange, MaskType)}\), denoting a submask confined to a contiguous 2D query–key region (see Fig. 3 below).
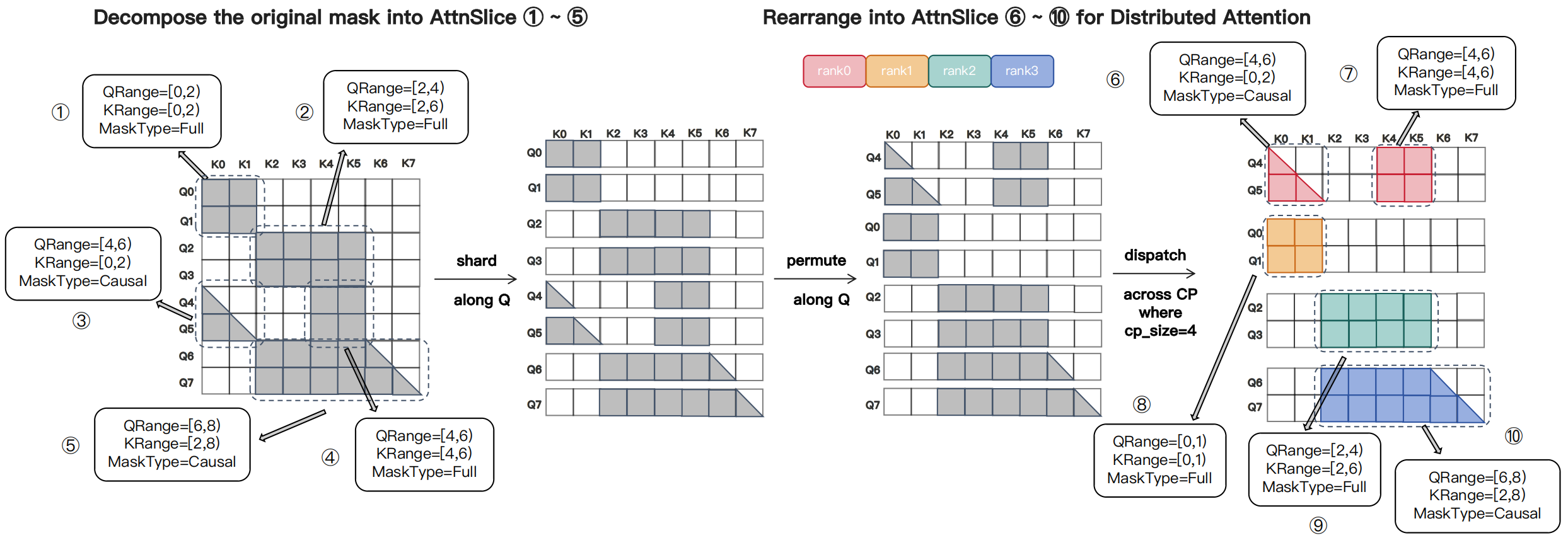
Fig. 3 Illustration of the \(\mathrm{AttnSlice}\) formulation for an irregular mask. The mask is decomposed into multiple \(\mathrm{AttnSlice}\) units, allowing fractal patterns to be re-expressed after redistribution across CP ranks to support distributed attention. Note that computation load balancing across CP ranks is not considered in this illustration.#
As illustrated in Fig. 4 below, this formulation expresses a wide range of attention masks—including the varlen block-causal mask used in Magi-1—as compositions of multiple triplets. These representations remain valid after sharding and rearrangement across ranks, making FFA well suited for distributed attention computation.
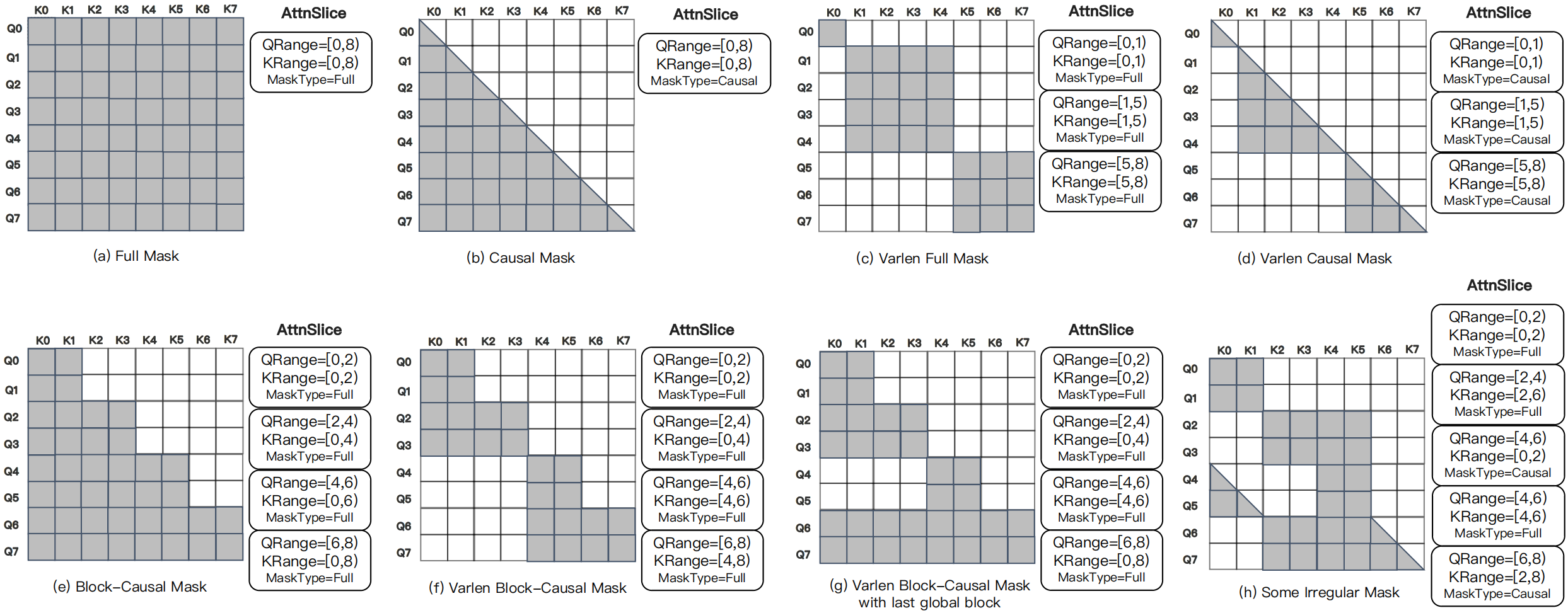
Fig. 4 Examples of mask patterns expressed using \(\mathrm{AttnSlice}\): (a)–(d) are standard FA3-compatible patterns; (e)–(h) are irregular masks beyond Flash-Attention’s capability—e.g., the varlen block-causal mask—which FFA handles seamlessly while preserving FA3-comparable performance.#
AttnSlice-level Parallelism in FFA#
Built on Flash-Attention 3 (FA3) kernels [Shah et al., 2024], FFA leverages Hopper GPUs’ TMA feature [NVIDIA, 2024] and implements \(\mathrm{AttnSlice}\)-level parallelism with atomic operations for correctness (illustrated in Fig. 5 below). FFA delivers MFU comparable to FA3 while supporting the flexible \(\mathrm{AttnSlice}\) formulation—see Attention Kernel Benchmark for detailed performance and flexibility comparisons.
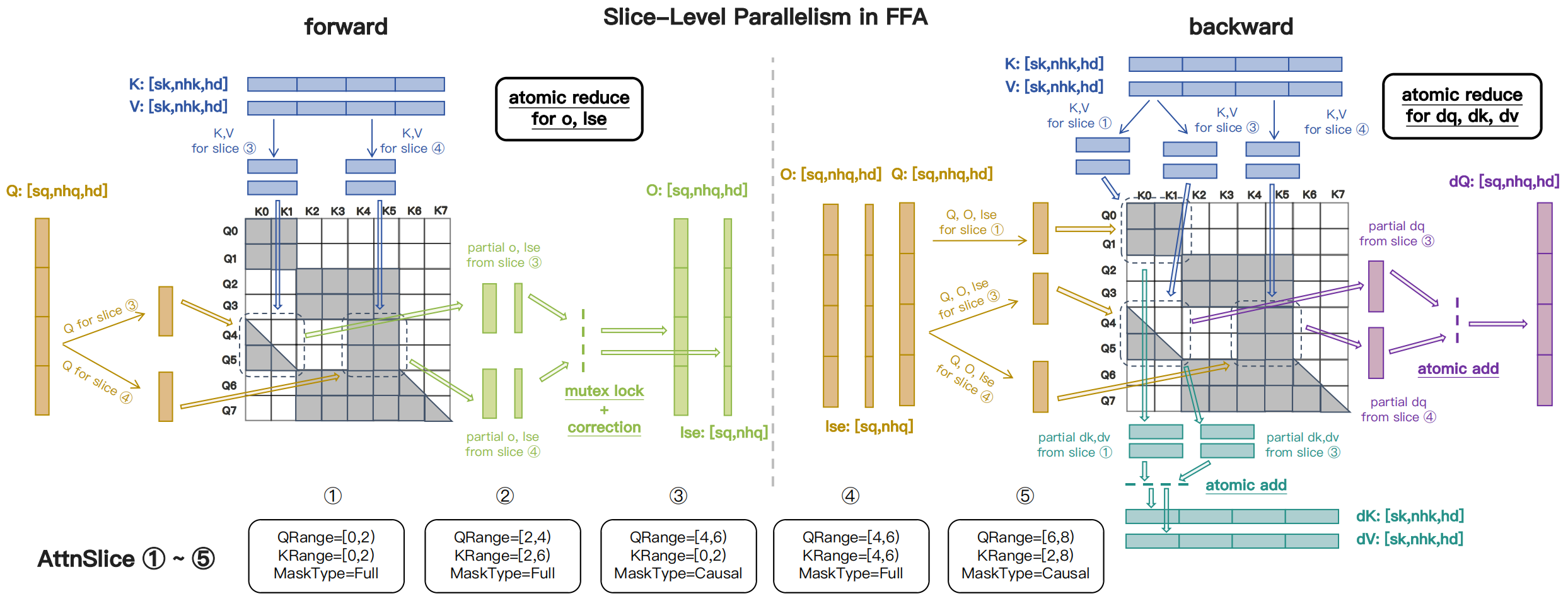
Fig. 5 Illustration of the FFA forward and backward kernels: data loading, on-chip computation, and atomic reduction for slice-level parallelism.#
Basic Mask Types in AttnSlice#
Although most mask patterns can be expressed with \(\mathrm{AttnSlice}\) using the common types \(\lbrace\texttt{FULL}, \texttt{CAUSAL}\rbrace\), some patterns—e.g., \(\textit{sliding-window}\)—become inefficient because they require expressing each row individually. To represent such patterns compactly, we introduce two additional mask types, \(\lbrace\texttt{INV-CAUSAL}, \texttt{BI-CAUSAL}\rbrace\). The following Fig. 6, Fig. 7, and Fig. 8 illustrate examples of the current \(4\) supported mask types.

Fig. 6 Illustrates the four supported mask types for seqlen_q == seqlen_k. Note: in this setting, \(\texttt{BI-CAUSAL}\) reduces to a mask where only the principal diagonal cells are valid.#

Fig. 7 Illustration of the four supported mask types when seqlen_q < seqlen_k. This configuration commonly occurs when employing \(\texttt{INV-CAUSAL}\) and \(\texttt{BI-CAUSAL}\) masks.#

Fig. 8 Illustration of the four supported mask types for seqlen_q > seqlen_k. Note that \(\texttt{BI-CAUSAL}\) is empty and contains no valid cells.#
Using the four supported mask types, we illustrate common \(\textit{sliding-window}\)-style masks expressed via the \(\mathrm{AttnSlice}\) formulation (see Fig. 9 below).
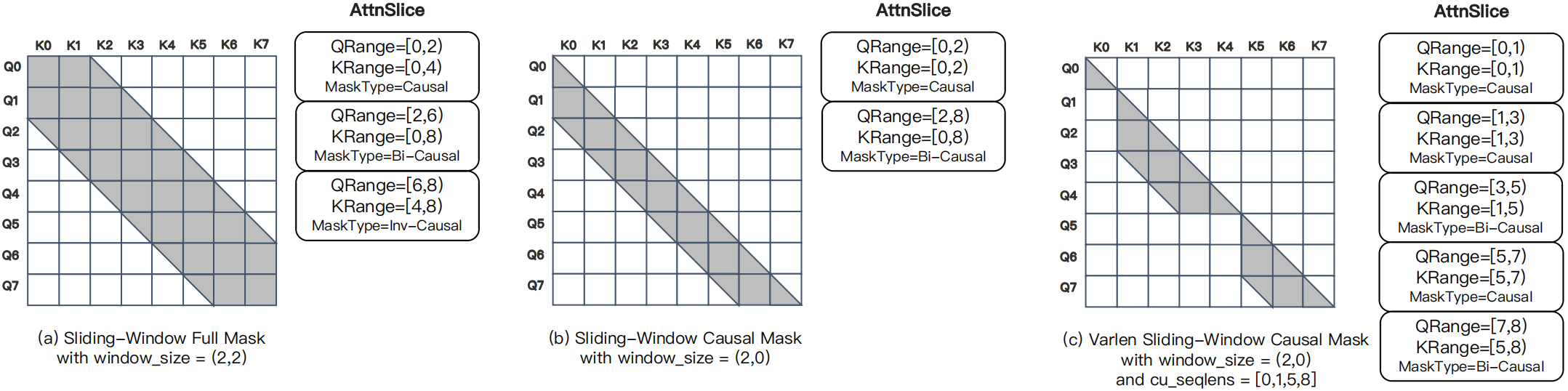
Fig. 9 Examples of common \(\textit{sliding-window}\)-style mask patterns formulated by \(\mathrm{AttnSlice}\).#
Computation Load-Balancing#
Dispatch Solver#
In context-parallel training, heterogeneous attention masks across CP ranks create imbalanced computational workloads. Ring-Attention (see Related Work) uses a partitioning strategy tailored to causal masks and therefore does not generalize to arbitrary patterns. To address this, we propose a generic, efficient dispatch solver that balances workload across CP ranks for diverse attention types.
Concretely, we adopt a chunk-wise permutable sharding: partition the global mask evenly along the query dimension into chunks, each associated with a submask area \(\lbrace(C_i, \mathrm{Area}(C_i))\rbrace_{i=1}^n\), where \(C_i\) denotes the i-th chunk, \(\mathrm{Area}(C_i)\) is its mask area, \(n = \frac{seqlen}{\textit{chunk\_size}}\), and \(\textit{chunk\_size}\) is a tunable granularity parameter.
These chunks are assigned equally to \(\textit{cp\_size}\) buckets so every bucket contains the same number of chunks (preserving token-level balance for non-attention stages). Each bucket’s total mask workload is the summed submask area, written as \(\lbrace(B_j, \mathrm{SumArea}(B_j))\rbrace_{j=1}^{\textit{cp\_size}}\).
Under this formulation, load balancing reduces to a combinatorial assignment problem: find an optimal mapping \(f^*: \lbrace C_i\rbrace_{i=1}^n \rightarrow \lbrace B_j\rbrace_{j=1}^{\textit{cp\_size}}\) that minimizes the maximum per-bucket area, as shown in the Eq (1) below.
Since this problem is NP-hard and mask patterns change across micro-batches, solving it exactly per iteration is impractical. We therefore use a practical greedy Min-Heap algorithm (illustrated in Fig. 10 below) that runs in \(O(n\log n)\) and yields a fast, effective assignment with minimal runtime overhead.

Fig. 10 Greedy Load-Balance Dispatch Algorithm via Min-Heap#
Static Attn Solver#
Upon dispatching tensors along the seqlen dimension into \(n\) chunks, the global mask is partitioned into \(n^2\) submasks and each CP rank is assigned with \(n\) submasks. Since each rank can process only one “host” submask along the principal diagonal of the global mask using local tensors, the remaining \(n\!-\!1\) “remote” submasks require communication. This yields two essential but non-trivial meta structures:
(1)
CalcMeta: Encodes each submask as \(\mathrm{AttnSlice}\) instances per rank (and per stage if using multi-stage overlap) and supplies the arguments required by theFFAkernels for calculation.(2)
CommMeta: Describes the data exchanges with other CP peers—what input tensors to fetch forFFAand how to reduce partial outputs per rank (and per stage if using multi-stage overlap)—producing the arguments forGroupCast/GroupReducekernels for communication (see group collective primitives for details).
To produce these, we design the attn solver data structure: it consumes the dispatch solver output and emits the CalcMeta and CommMeta needed to run distributed attention (forward and backward), i.e., the argument bundles for FFA and GroupCast/GroupReduce on each CP rank and stage. And we initially provide the static attn solver implementation that builds CalcMeta and CommMeta during the data preprocessing stage from the dispatch solver results, then invokes the overlap solver to derive multi‑stage schedules.
However, This static attn solver is based on the strong assumption that the global mask is static, i.e. (1) known at the data-processing stage for each micro-batch and (2) remains unchanged across the whole forward/backward passes at all attention layers. It also restricts to the kv-comm only scheduling, that only \(\mathrm{KV}\)-related tensors are allowed to be communicated while \(\mathrm{QO}\)-related tensors stay local—limiting scheduling flexibility and overlap potential.
Dynamic Attn Solver#
The static attn solver handles most standard training cases but is limited and suboptimal for dynamic mask scenarios—e.g., layer-varying hybrid attention [MiniMax et al., 2025] or dynamic sparse masks determined at runtime [DeepSeek-AI et al., 2025, Yuan et al., 2025].
To address this, we are developing an experimental dynamic attn solver that dynamically balances computation (w/o relying on initial dispatch results by dispatch solver) and minimizes communication under general scheduling with qo-comm enabled, relaxing the heuristics of the current kv-comm only scheduling. Then it will be able to generate CalcMeta and CommMeta on‑the‑fly with negligible overhead during each attention-layer forward pass.
See the seperate blog post for more details about the motivation, design, implementation, and preliminary results of the dynamic attn solver.
Zero-Redundant Communication Primitives#
Ring P2P Redundancy Analysis#
Ring-style implementations rely on point-to-point (P2P) send/recv primitives that lack fine-grained communication control, causing unnecessary data movement. To quantify this, we record remote key-value (\(\mathrm{KV}\)) requests and their gradients (\(\mathrm{dKV}\)) under a causal mask as a simple example shown in Fig. 11: in the forward pass \(\mathrm{KV}_0\) must be sent to all devices via BroadCast, while \(\mathrm{dKV}_0\) requires to be reduced via AllReduce during the backward. However, \(\mathrm{KV}_7\) is required ONLY locally for its host \(rank_7\) yet still circulates across all devices. This redundant even dissemination—and its cost—becomes more severe for varlen mask patterns.
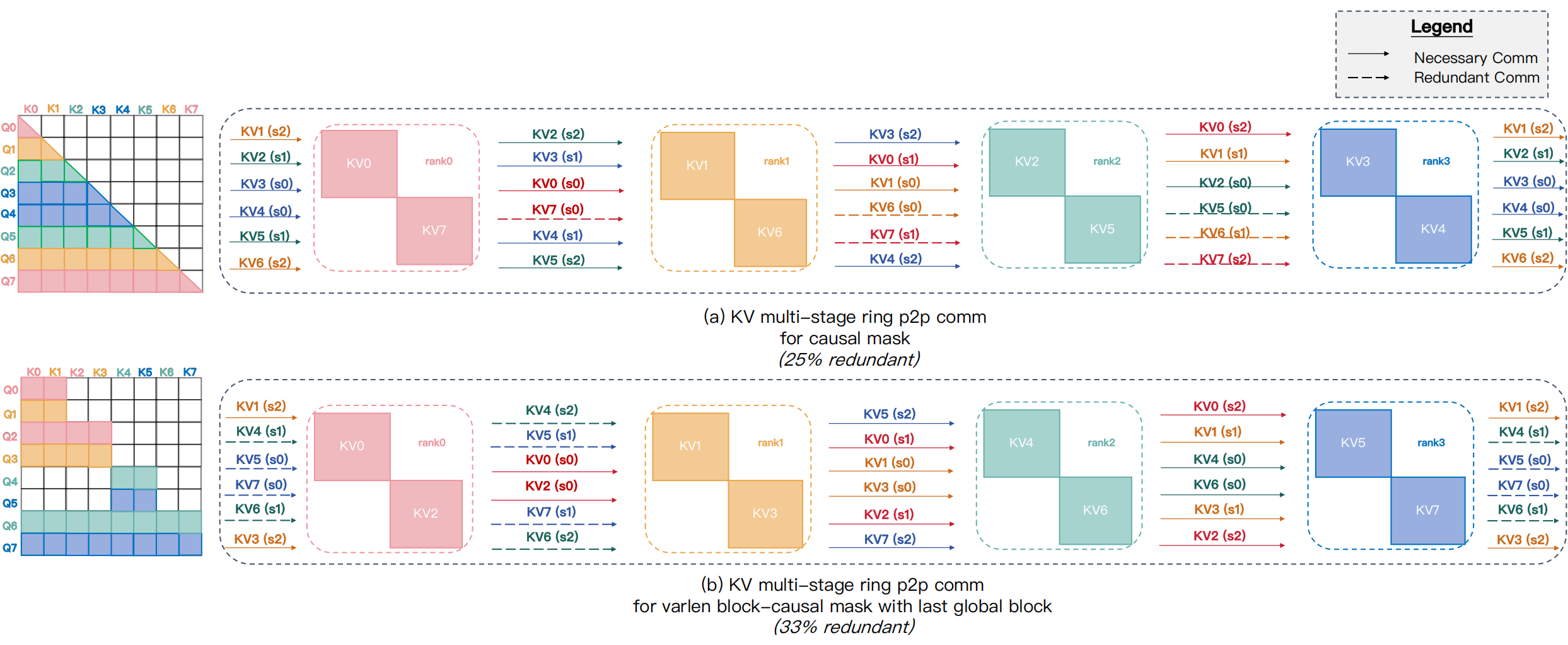
Fig. 11 Examples of redundant communication in Ring P2P with heterogeneous masks: (a) a simple causal mask incurs 25% redundant communication; (b) irregular masks, e.g., the varlen block-causal mask with the last global block, can exceed 33% redundancy.#
Group Collective Primitives#
To address this, as illustrated in the Fig. 12 below, we introduce two communication primitives: GroupCast and GroupReduce, which model the communication patterns of low-demand \(\mathrm{KV}\) and \(\mathrm{dKV}\). For example, in the causal mask, \(\mathrm{KV}_5\) on \(\mathrm{rank}_2\) is required only by \(\{\mathrm{Q}_6,\mathrm{Q}_7\}\) and should be sent exclusively to the target ranks \(\{\mathrm{rank}_0, \mathrm{rank}_1\}\) via GroupCast, while the partial \(\mathrm{dKV}_5\) is collected and reduced back to \(\mathrm{rank}_2\) via GroupReduce accordingly.
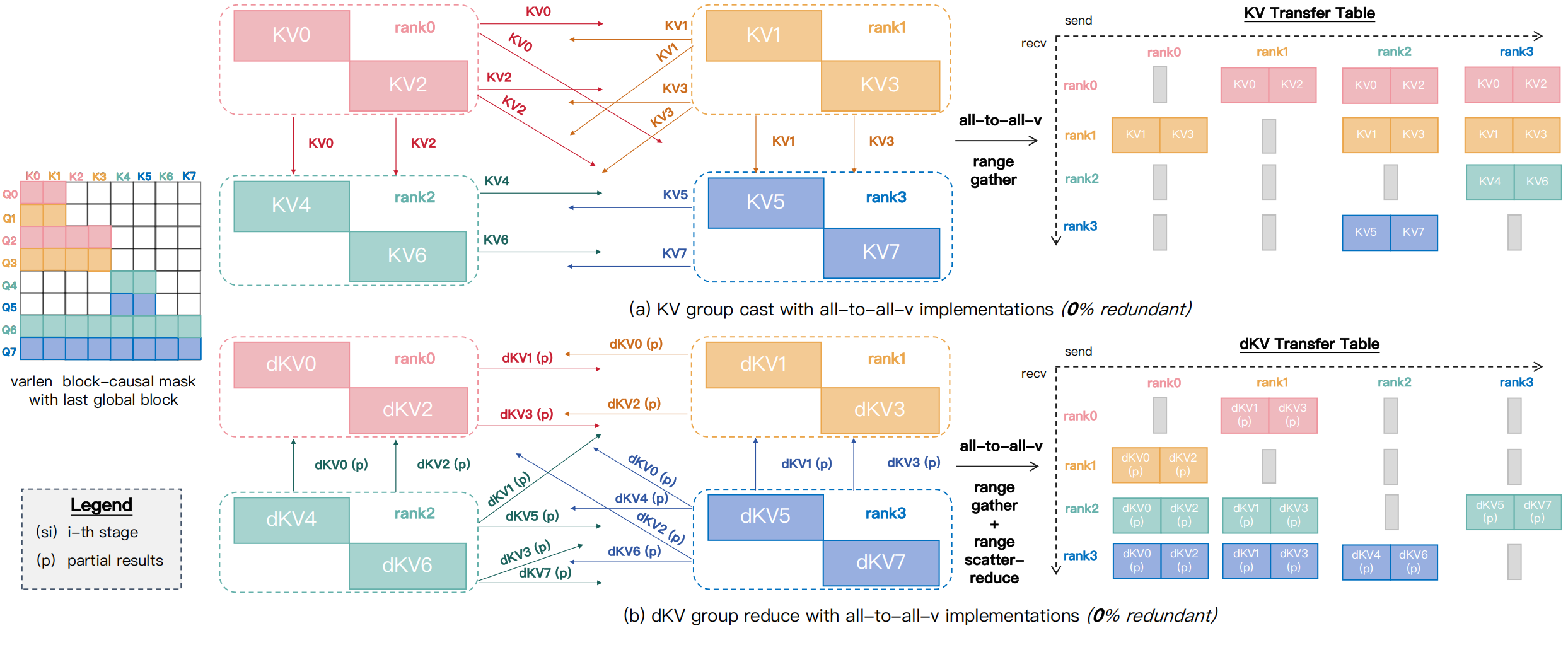
Fig. 12 Illustration of GroupCast/GroupReduce primitives implemented atop AlltoAll-v to achieve zero redundancy, shown using the varlen block-causal mask with the last global block. (a) For forward and backward passes, GroupCast builds a transfer table for \(\mathrm{KV}\) send/receive buffers, invokes AlltoAll-v, and uses a custom Range-Gather kernel for pre-/post-processing. (b) In the backward pass, GroupReduce aggregates partial \(\mathrm{dKV}\) via AlltoAll-v, employing Range-Gather for pre-processing and Range-Scatter-Reduce for post-processing.#
AlltoAll-v Implementation#
Since no existing communication kernels support group collectives, we prototyped GroupCast and GroupReduce on top of AlltoAll-v, achieving zero-redundant communication in forward and backward passes (see Fig. 12). This approach, however, requires additional pre-/post-processing: GroupCast must re-permute inputs for AlltoAll-v and restore outputs (Range-Gather), and GroupReduce also performs a reduction on the output (Range-Scatter-Reduce). Although we implemented these steps using optimized Triton kernels, the extra overhead remains non‑negligible and might impact end-to-end performance.
Besides the extra pre-/post-processing D2D overhead, another obscure cost of the AlltoAll-v implementation is that it permits only a single send/recv buffer pair per peer pair and therefore does not natively support “cast” semantics. Thus, to send a tensor from one rank to a subset of peers of size \(m\), one must allocate \(m\) separate send buffers—one per destination—and transfer them individually, even though the data are identical. This duplication incurs substantial communication overhead, which is particularly severe when the CP group includes internode peers using RDMA, whose bandwidth is much lower than intranode NVLink.
Native Implementation#
To mitigate the extra overhead of the AlltoAll-v implementation aforementioned, we develop a native CUDA kernel implementation of group collectives inspired by DeepEP [Zhao et al., 2025]. It not only removes the pre-/post-processing D2D copies but also significantly improves efficiency via the optimization of RDMA transfer de-duplication, particularly for hierarchical CP groups spanning internode and intranode peers.
Although further optimizations remain, gains are already evident in the Attention Benchmark, particularly when scaling up the hierarchical CP group size. Please see the separate blog post for more details about the motivation, design, implementation, and experimental results of the native implementation of group collectives.
Multi-Stage Computation/Communication Overlap#
Scheduling with KV-Comm Only#
Leveraging previous optimizations, we combine an optimized kernel, load-balanced dispatch, and zero-redundant primitives to minimize communication overhead and maximize computation throughput individually. Now, to drive true linear scalability, we introduce an adaptive multi-stage computation/communication overlap strategy that effectively hides communication latency and can be tuned manually or automatically.
Similar to prior works [He et al., 2024, Liu et al., 2023, Zhao et al., 2023], we schedule pipeline stages to overlap computation and communication in both forward and backward passes (see Fig. 13). Each \(\mathrm{rank}_i\) partitions its remote \(\mathrm{KV}\)/\(\mathrm{dKV}\) exchanges into stages.
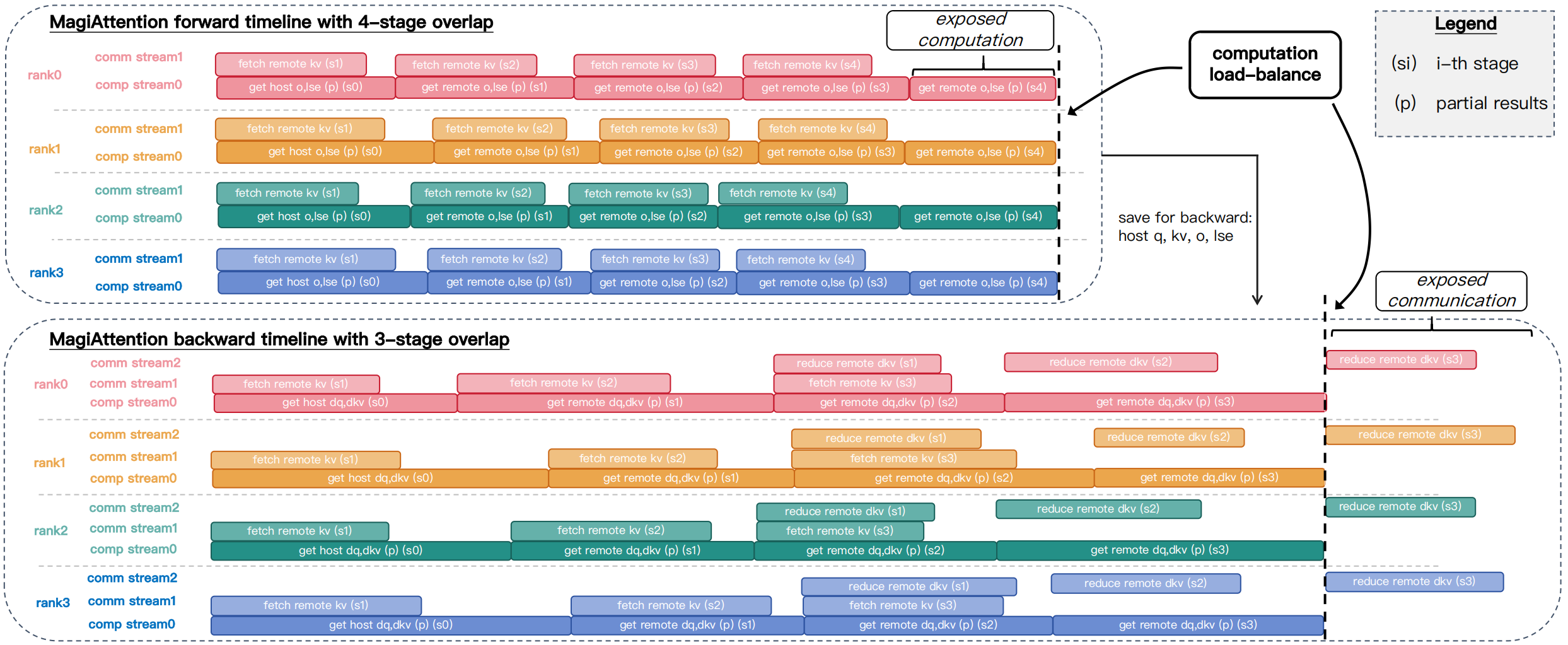
Fig. 13 Illustration of Magi Attention’s multi-stage overlap scheduling. (a) Forward pass — a 4-stage schedule that overlaps computation (partial \(\mathrm{O}\) and \(\mathrm{LSE}\)) with prefetching of next-stage \(\mathrm{KV}\) requests, hiding communication latency except for the final stage’s computation. (b) Backward pass — a 3-stage schedule that overlaps computation (partial \(\mathrm{dQ}\), \(\mathrm{dKV}\)), next-stage \(\mathrm{KV}\) prefetches, and reduction of prior \(\mathrm{dKV}\) requests, leaving only the final stage of partial \(\mathrm{dKV}\) reduction exposed.#
In the forward pass, the scheduler launches the GroupCast kernel to prefetch the next \((i\!+\!1)\)-th stage of remote \(\mathrm{KV}\) while asynchronously executing the current \(i\)-th stage of the FFA kernel for partial attention. Since local qkv is always available for the initial stage, all communication latency is fully hidden, leaving only the final remote stage’s computation exposed.
In the backward pass, the scheduler prefetches the next \((i\!+\!1)\)-th stage of \(\mathrm{KV}\) and invokes the GroupReduce kernel to reduce the prior \((i\!-\!1)\)-th stage of partial \(\mathrm{dKV}\) before executing the current \(i\)-th attention stage. This overlap conceals communication latency across stages, exposing only the final stage of partial \(\mathrm{dKV}\) reduction.
Scheduling with QO-Comm Enabled#
Initially, we follow the legacy heuristic that only \(\mathrm{KV}\)-related tensors are communicated while \(\mathrm{QO}\)-related tensors remain local, a common practice in prior works [Fang and Zhao, 2024, Liu et al., 2023]. This simplifies scheduling and often reduces communication, particularly in GQA settings where \(\mathrm{KV}\) typically has lower volume than \(\mathrm{QO}\).
However, this heuristic is not fundamental and can be suboptimal for certain mask patterns and training setups. We therefore support a more general scheduler that permits communication of \(\mathrm{QO}\) when advantageous. In the forward pass, the scheduler will prefetch the next stage of remote \(\mathrm{Q}\) in addition to remote \(\mathrm{KV}\), overlapping both of them with the current FFA computation. And a major difference to \(\mathrm{KV}\)-only schedule is that we also need to apply \(\mathrm{LSE}\)-reduction for the previous stage’s partial \(\mathrm{O,LSE}\) while overlapping with the current stage of computation.
In the backward pass, the scheduler will prefetch the next stage of remote \(\mathrm{KV}\) and \(\mathrm{Q,O,dO,LSE}\) and concurrently sum-reduce the prior stage’s partial \(\mathrm{dKV}\) and \(\mathrm{dQ}\), overlapping with the current FFA backward computation.
Although the scheduler itself is already supported, enabling this mode also requires the dynamic attn solver to emit the corresponding CalcMeta and CommMeta for FFA and the group-collective kernels, which is under active development (see Dynamic Attn Solver). We will release it soon and continue to optimize it for better performance.
How to Ensure Kernels Actually Overlapped#
While the CPU scheduler controls kernel launch order to favor overlap, the GPU Hyper-Q driver [Bradley, 2013] ultimately determines actual execution order non‑deterministically, influenced by transient GPU resource occupancy as well. Ensuring reliable overlap between computation and communication kernels is therefore non‑trivial.
See the separate blog post for practical techniques and our specific novel approaches.
Dynamic Overlap Stage Search#
Warning
In practice, \(\textit{overlap\_degree}\) is typically tuned manually in \(\{1,2,3,4\}\). Automatic search by the overlap solver often underperforms because it requires accurate estimates of computation-to-communication ratios. We therefore recommend trying manual tuning for a few iterations to identify a suitable \(\textit{overlap\_degree}\) before enabling automatic search, which we will continue to improve for greater robustness.
To control overlap granularity, we introduce the tunable hyperparameter \(\textit{overlap\_degree}\), indicating the number of remote stages to be partitioned, which adapts to varying computation-to-communication ratios across training setups, microbatches, and between forward and backward passes. It can be set manually by the user on their own training setup. Or, we provide an algorithm to choose automatically by the overlap solver using the dynamic search described in the following Fig. 14.

Fig. 14 Dynamic Overlap Stage Search Algorithm#
Experiments#
Attention Benchmark#
To evaluate the performance and flexibility of FFA kernels and to validate the distributed scalability of MagiAttention for ultra-long, heterogeneous-mask training, we benchmark throughput on modern GPUs (e.g., Hopper and Blackwell) for both kernels and distributed attention modules in forward and backward passes across diverse mask patterns (standard and irregular), comparing against state-of-the-art kernel- and distributed-level baselines.
We present representative distributed-level benchmarks below for the most commonly used varlen causal mask on both H100 and B200 GPUs, highlighting MagiAttention’s performance and scalability versus other leading CP strategies.
For detailed benchmark settings and results, see the separate blog post.
H100#
Fig. 15 (a) Forward Pass#
Fig. 16 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on H100 for the varlen causal mask.
B200#
Fig. 17 (a) Forward Pass#
Fig. 18 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on B200 for the varlen causal mask.
Miscellaneous#
Preliminaries#
Flash Attention 2 Math Derivation#
See the separate blog post for a detailed mathematical derivation of the Flash-Attention 2 forward and backward passes, which serves as the foundation for our Flex-Flash-Attention kernel design.
Extended Functionalities#
FFA_FA4 Backend for Blackwell#
Since FFA is built on FA3 kernels that are available only on Hopper, we provide a temporary FFA_FA4 backend to enable MagiAttention on Blackwell. FFA_FA4 implements flexible masking via an HSTU Function representation based on Flash-Attention 4 (FA4). See the separate blog post for design details and the Attention Kernel Benchmark for Blackwell performance comparisons.
Attention Sink#
See the separate blog post for a technical description of how we natively support learnable attention sink mechanism in Flex-Flash-Attention (kernel-level), MagiAttention (distributed-level), and Flash-Attention (one of the MagiAttention Extensions).
Muon QK-Clip#
See the separate blog post for a technical description of how we natively support Muon QK-clip technique in Flex-Flash-Attention (kernel-level) and MagiAttention (distributed-level).
JIT Compilation in FFA#
See the separate blog post for a technical description of how we support Just-In-Time (JIT) compilation in Flex-Flash-Attention, to reduce pre-building overhead and deliver optimized kernels for varied attention patterns and training scenarios.
Optimization Techniques#
Optimize Sparse Attention in FFA#
Sparse Attention is a promising research direction to trade model capacity for sub-quadratic attention cost using (static/dynamic) highly-sparse mask patterns [Beltagy et al., 2020, Child et al., 2019, Zaheer et al., 2021, Zhang et al., 2025]. Recent works such as NSA [Yuan et al., 2025] and DSA [DeepSeek-AI et al., 2025] from DeepSeek introduce novel (dynamic) trainable sparse attention mechanisms, bringing new opportunities for efficient training. Therefore we’ve been implementing targeted optimizations on FFA for sparse masks to natively support (distributed) trainable sparse attention, and share our preliminary results in the separate blog post.
Next-Generation Design#
Distributed-Native FFA#
See the separate blog post for a technical proposal for the next major version update of MagiAttention: a distributed-native FFA kernel with fused warp-level communication primitives to further reduce communication overhead and kernel launch latency.
Attention Engine for Inference#
See the separate blog post for a technical proposal of the next-generation design named Attention Engine, which targets efficient distributed attention serving for inference scenarios.
Future Work#
[WIP] Optimize
FFAkernels on Hopper for improved performance, with emphasis on sparse attention scenarios.[WIP] Implement native
GroupCastandGroupReducecommunication kernels to reduce communication overhead and lower compute occupancy.[WIP] Extend the
dynamic attn solverto better handle dynamic mask patterns (e.g., hybrid attention, sparse attention) for lower communication and improved load balance.Optimize
static attn solverto reduce CPU meta-info overhead.Support individual
OverlapConfigfor forward and backward passes, and further extend theoverlap solverto automatically determine optimal overlap strategies for forward and backward passes separately.Implement native
FFAkernels on Blackwell to replace the temporaryFFA_FA4backend.Port
FFAto additional GPU architectures (e.g., Ampere).Extend attention benchmarking for more GPU architectures beyond H100 and B200 (e.g., B300 and A100).
Expand documentation with more examples and a tuning guide for varied training scenarios.
Prepare a standalone technical report/paper detailing MagiAttention.
Add support for additional attention patterns, including cross-attention and inference use cases.
Upgrade
MagiAttentionto a distributed-nativeFFAkernel with fused warp-level communication primitivesImplement
Attention Enginefor distributed attention serving in inference scenarios.
Done
Support MagiAttention on Blackwell with a temporary
FFA_FA4backend.Support
dynamic attn solverwith query/output communication pattern to reduce communication in cases where KV-only communication is suboptimal.Prototype native
GroupCastandGroupReduceprimitives with inter-/intra-node hierarchical optimization based on DeepEP.Support learnable attention sink integration with StreamingLLM.
Refactor
dist attn solverto support all four mask types and full overlapping strategies.Improve the
dispatch solverto reduce communication volume while maintaining compute balance, especially for varlen masks.Build a comprehensive
CP Benchmarkvalidating MagiAttention across mask patterns and training settings.Provide
DocumentationcoveringInstallation,QuickStart,API reference, andEnvironment Variables.
Citation#
If you find MagiAttention useful in your research, please cite:
@misc{magiattention2025,
title={MagiAttention: A Distributed Attention Towards Linear Scalability for Ultra-Long Context, Heterogeneous Mask Training},
author={Zewei, Tao and Yunpeng, Huang},
year={2025},
howpublished={\url{https://github.com/SandAI-org/MagiAttention/}},
}
References#
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: the long-document transformer. 2020. URL: https://arxiv.org/abs/2004.05150, arXiv:2004.05150.
Thomas Bradley. Hyper-q example. 2 2013. URL: https://developer.download.nvidia.com/compute/DevZone/C/html_x64/6_Advanced/simpleHyperQ/doc/HyperQ.pdf.
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, Ethan He, Hongxu Yin, Pavlo Molchanov, Jan Kautz, Linxi Fan, Yuke Zhu, Yao Lu, and Song Han. Longvila: scaling long-context visual language models for long videos. 2024. URL: https://arxiv.org/abs/2408.10188, arXiv:2408.10188.
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. 2019. URL: https://arxiv.org/abs/1904.10509, arXiv:1904.10509.
Tri Dao. Flashattention-2: faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
Tri Dao, Guessous Driss, and Tsang Henry. Flashattention cute module [software documentation]. GitHub Repository README, 2025. URL: Dao-AILab/flash-attention.
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Li, Haofen Liang, Haoran Wei, Haowei Zhang, Haowen Luo, Haozhe Ji, Honghui Ding, Hongxuan Tang, Huanqi Cao, Huazuo Gao, Hui Qu, Hui Zeng, Jialiang Huang, Jiashi Li, Jiaxin Xu, Jiewen Hu, Jingchang Chen, Jingting Xiang, Jingyang Yuan, Jingyuan Cheng, Jinhua Zhu, Jun Ran, Junguang Jiang, Junjie Qiu, Junlong Li, Junxiao Song, Kai Dong, Kaige Gao, Kang Guan, Kexin Huang, Kexing Zhou, Kezhao Huang, Kuai Yu, Lean Wang, Lecong Zhang, Lei Wang, Liang Zhao, Liangsheng Yin, Lihua Guo, Lingxiao Luo, Linwang Ma, Litong Wang, Liyue Zhang, M. S. Di, M. Y Xu, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Mingxu Zhou, Panpan Huang, Peixin Cong, Peiyi Wang, Qiancheng Wang, Qihao Zhu, Qingyang Li, Qinyu Chen, Qiushi Du, Ruiling Xu, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, Runqiu Yin, Runxin Xu, Ruomeng Shen, Ruoyu Zhang, S. H. Liu, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shaofei Cai, Shaoyuan Chen, Shengding Hu, Shengyu Liu, Shiqiang Hu, Shirong Ma, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, Songyang Zhou, Tao Ni, Tao Yun, Tian Pei, Tian Ye, Tianyuan Yue, Wangding Zeng, Wen Liu, Wenfeng Liang, Wenjie Pang, Wenjing Luo, Wenjun Gao, Wentao Zhang, Xi Gao, Xiangwen Wang, Xiao Bi, Xiaodong Liu, Xiaohan Wang, Xiaokang Chen, Xiaokang Zhang, Xiaotao Nie, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xingkai Yu, Xingyou Li, Xinyu Yang, Xinyuan Li, Xu Chen, Xuecheng Su, Xuehai Pan, Xuheng Lin, Xuwei Fu, Y. Q. Wang, Yang Zhang, Yanhong Xu, Yanru Ma, Yao Li, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Wang, Yi Qian, Yi Yu, Yichao Zhang, Yifan Ding, Yifan Shi, Yiliang Xiong, Ying He, Ying Zhou, Yinmin Zhong, Yishi Piao, Yisong Wang, Yixiao Chen, Yixuan Tan, Yixuan Wei, Yiyang Ma, Yiyuan Liu, Yonglun Yang, Yongqiang Guo, Yongtong Wu, Yu Wu, Yuan Cheng, Yuan Ou, Yuanfan Xu, Yuduan Wang, Yue Gong, Yuhan Wu, Yuheng Zou, Yukun Li, Yunfan Xiong, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Z. F. Wu, Z. Z. Ren, Zehua Zhao, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhibin Gou, Zhicheng Ma, Zhigang Yan, Zhihong Shao, Zhixian Huang, Zhiyu Wu, Zhuoshu Li, Zhuping Zhang, Zian Xu, Zihao Wang, Zihui Gu, Zijia Zhu, Zilin Li, Zipeng Zhang, Ziwei Xie, Ziyi Gao, Zizheng Pan, Zongqing Yao, Bei Feng, Hui Li, J. L. Cai, Jiaqi Ni, Lei Xu, Meng Li, Ning Tian, R. J. Chen, R. L. Jin, S. S. Li, Shuang Zhou, Tianyu Sun, X. Q. Li, Xiangyue Jin, Xiaojin Shen, Xiaosha Chen, Xinnan Song, Xinyi Zhou, Y. X. Zhu, Yanping Huang, Yaohui Li, Yi Zheng, Yuchen Zhu, Yunxian Ma, Zhen Huang, Zhipeng Xu, Zhongyu Zhang, Dongjie Ji, Jian Liang, Jianzhong Guo, Jin Chen, Leyi Xia, Miaojun Wang, Mingming Li, Peng Zhang, Ruyi Chen, Shangmian Sun, Shaoqing Wu, Shengfeng Ye, T. Wang, W. L. Xiao, Wei An, Xianzu Wang, Xiaowen Sun, Xiaoxiang Wang, Ying Tang, Yukun Zha, Zekai Zhang, Zhe Ju, Zhen Zhang, and Zihua Qu. Deepseek-v3.2: pushing the frontier of open large language models. 2025. URL: https://arxiv.org/abs/2512.02556, arXiv:2512.02556.
Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim Alabdulmohsin, Avital Oliver, Piotr Padlewski, Alexey Gritsenko, Mario Lučić, and Neil Houlsby. Patch n' pack: navit, a vision transformer for any aspect ratio and resolution. 2023. URL: https://arxiv.org/abs/2307.06304, arXiv:2307.06304.
Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang, and Horace He. Flex attention: a programming model for generating optimized attention kernels. 2024. URL: https://arxiv.org/abs/2412.05496, arXiv:2412.05496.
Jiarui Fang and Shangchun Zhao. Usp: a unified sequence parallelism approach for long context generative ai. 2024. URL: https://arxiv.org/abs/2405.07719, arXiv:2405.07719.
Hao Ge, Junda Feng, Qi Huang, Fangcheng Fu, Xiaonan Nie, Lei Zuo, Haibin Lin, Bin Cui, and Xin Liu. Bytescale: efficient scaling of llm training with a 2048k context length on more than 12,000 gpus. 2025. URL: https://arxiv.org/abs/2502.21231, arXiv:2502.21231.
Diandian Gu, Peng Sun, Qinghao Hu, Ting Huang, Xun Chen, Yingtong Xiong, Guoteng Wang, Qiaoling Chen, Shangchun Zhao, Jiarui Fang, Yonggang Wen, Tianwei Zhang, Xin Jin, and Xuanzhe Liu. Loongtrain: efficient training of long-sequence llms with head-context parallelism. 2024. URL: https://arxiv.org/abs/2406.18485, arXiv:2406.18485.
Horace He, Less Wright, Luca Wehrstedt, Tianyu Liu, and Wanchao Liang. [distributed w/ torchtitan] introducing async tensor parallelism in pytorch. https://discuss.pytorch.org/t/distributed-w-torchtitan-introducing-async-tensor-parallelism-in-pytorch/209487, 2024.
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: system optimizations for enabling training of extreme long sequence transformer models. arXiv preprint arXiv:2309.14509, 2023. URL: https://arxiv.org/pdf/2309.14509.
Vijay Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation recomputation in large transformer models. 2022. arXiv:2205.05198.
Shenggui Li, Fuzhao Xue, Chaitanya Baranwal, Yongbin Li, and Yang You. Sequence parallelism: long sequence training from system perspective. arXiv preprint arXiv:2105.13120, 2021.
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context. arXiv preprint arXiv:2310.01889, 2023.
MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, and Zijia Wu. Minimax-01: scaling foundation models with lightning attention. 2025. URL: https://arxiv.org/abs/2501.08313, arXiv:2501.08313.
NVIDIA. Accelerating transformers with nvidia cudnn 9. https://developer.nvidia.com/blog/accelerating-transformers-with-nvidia-cudnn-9/, 2024. Accessed: 2024-12-12.
PyTorch. Torch.nn.functional.scaled_dot_product_attention - pytorch 2.6 documentation. https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html.
Markus N Rabe and Charles Staats. Self-attention does not need $ o (nˆ 2) $ memory. arXiv preprint arXiv:2112.05682, 2021.
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: fast and accurate attention with asynchrony and low-precision. 2024. URL: https://arxiv.org/abs/2407.08608, arXiv:2407.08608.
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: training multi-billion parameter language models using model parallelism. 2020. arXiv:1909.08053.
GitHub User. [question] why should cuda_device_max_connections=1 should be set when using seq_parallel or async comm? NVIDIA/Megatron-LM#533, 2023.
Guoxia Wang, Jinle Zeng, Xiyuan Xiao, Siming Wu, Jiabin Yang, Lujing Zheng, Zeyu Chen, Jiang Bian, Dianhai Yu, and Haifeng Wang. Flashmask: efficient and rich mask extension of flashattention. 2025. URL: https://arxiv.org/abs/2410.01359, arXiv:2410.01359.
Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, and others. Overlap communication with dependent computation via decomposition in large deep learning models. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 93–106. 2022.
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, and Bin Cui. Data-centric and heterogeneity-adaptive sequence parallelism for efficient llm training. 2024. URL: https://arxiv.org/abs/2412.01523, arXiv:2412.01523.
Zongwu Wang, Fangxin Liu, Mingshuai Li, and Li Jiang. Tokenring: an efficient parallelism framework for infinite-context llms via bidirectional communication. 2024. URL: https://arxiv.org/abs/2412.20501, arXiv:2412.20501.
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y. X. Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. Native sparse attention: hardware-aligned and natively trainable sparse attention. 2025. URL: https://arxiv.org/abs/2502.11089, arXiv:2502.11089.
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: transformers for longer sequences. 2021. URL: https://arxiv.org/abs/2007.14062, arXiv:2007.14062.
Geng Zhang, Xuanlei Zhao, Kai Wang, and Yang You. Training variable sequences with data-centric parallel. 2024.
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattention: accurate and training-free sparse attention accelerating any model inference. 2025. URL: https://arxiv.org/abs/2502.18137, arXiv:2502.18137.
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. Deepep: an efficient expert-parallel communication library. deepseek-ai/DeepEP, 2025.
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, and others. Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277, 2023.
zhuzilin. [feature request] balancing computation with zigzag blocking. zhuzilin/ring-flash-attention#2, Feb 2024.