Support Muon QK-Clip#
Introduction#
The Muon optimizer [Jordan et al., 2024], which leverages matrix orthogonalization, has shown faster convergence than traditional optimizers such as Adam [Kingma and Ba, 2017, Loshchilov and Hutter, 2019] on smaller language models and was subsequently demonstrated to scale to large models by Kimi [Liu et al., 2025].
To mitigate training instability when scaling Muon, Kimi proposed several theoretically motivated techniques [Liu et al., 2025, Team et al., 2026]; among them, the QK-Clip method from Kimi K2 [Team et al., 2026] is essential for preventing loss spikes and divergence caused by exploding attention logits.
QK-Clip requires tracking the maximum attention logits (max_logits) over the entire attention matrix \(S := QK^\mathrm T\), which is non-trivial because implementations based on Flash Attention typically avoid materializing the full attention matrix for memory efficiency [Dao, 2023, Dao et al., 2022]. This challenge is compounded in distributed setups with context parallelism (CP), where the attention matrix may be partitioned across CP ranks.
We address these challenges by adding native support for (distributed) Muon QK-Clip at both the kernel level in Flex-Flash-Attention (FFA) and the distributed level in MagiAttention, and present a concise API, implementation details, and empirical results below.
User Interface#
Previously, the APIs of flex_flash_attn_func and calc_attn returned a tuple of (out, lse), following Flash Attention style. To support (distributed) Muon QK-Clip and maybe other features in the future, we generalize the interface to return a tuple of (out, meta), where the meta is an instance of dataclass AttnForwardMeta, containing the fields that are useful but non-trivial to access out of the core-attention forward pass, such as lse and max_logits.
As shown in the following code snippets, With this return type, you can access the original lse tensor easily as meta.lse, and optionally the maximum logits tensor as meta.max_logits if you set the argument return_max_logits=True (defaults to False to return None). This meta-based design allows adding new fields for new features without breaking existing code.
Warning
Enabling return_max_logits=True for the first time will trigger a Just-In-Time (JIT) compilation since it is not included in the pre-built kernels of FFA, which may cause a one-time delay. Subsequent calls will use the cached kernel and run at full speed.
See more details about JIT compilation in FFA in the separate blog post.
For
flex_flash_attn_func:out, meta = flex_flash_attn_func( q, k, v, q_ranges, k_ranges, attn_type_map, return_max_logits=True ) lse = meta.lse # shape = (seqlen_q, num_heads_q), dtype=float32 max_logits = meta.max_logits # shape = (num_heads_q,), dtype=float32, or None if return_max_logits=False
For
calc_attn:out, meta = calc_attn( q, k, v, key, return_max_logits=True ) local_lse = meta.lse # shape = (local_seqlen_q, num_heads_q), dtype=float32 global_max_logits = meta.max_logits # shape = (num_heads_q,), dtype=float32, or None if return_max_logits=False
Implementation#
Kernel-Level Implementation in FFA#
To compute the maximum attention logits:
with flexible attention masking for each attention head in the FFA forward kernel, we adopt a two-level reduction strategy:
Intra-block Reduction: Within each CUDA block, after each worktile epilogue, threads perform a thread-level reduction to compute the
max_logitsover their assigned rows. Warp-level shuffle reduction aggregates per-warp maxima, and the first lane in each warp atomically updates the shared buffersmem_max_logits[head_q_idx]using a lock-free atomic-max. InPackGQAmode, where multiple query heads share key-value heads, each row’s max is atomically written directly to the correspondingsmem_max_logits[head_q_idx].Inter-block Reduction: Once a block has processed all its worktiles, threads synchronize to ensure intra-block reductions are complete, read the block-reduced
max_logitsfrom shared memory, multiply it bysoftmax_scalefor consistency with scaled attention scores, and atomically update the global buffergmem_max_logits[head_q_idx].Memory Allocation: Each block allocates a shared buffer
smem_max_logitssized to the number of attention heads (currently limited up to128), initialized to-inf. The global buffergmem_max_logitshas shape(num_heads_q,), dtypefloat32, and is also initialized to-inf.Atomic Maximum: Updates use a lock-free compare-and-swap atomic-max to ensure thread-safe, lockless updates across threads and blocks. If a larger value is already present, the updating thread can exit immediately, minimizing contention.
Distributed-Level Implementation in MagiAttention#
To compute the global maximum attention logits from the partial results computed on each CP rank for each stage:
we also need to adopt a two-level reduction strategy:
Inter-stage Reduction: On each CP rank, allocate a per-rank accumulative buffer
partial_max_logitsand pass it into theFFAforward kernel for every stage to accumulate stage-levelmax_logitsper attention head.Inter-rank Reduction: After stage accumulation, perform an
AllReducewithreduce_op=maxacross CP ranks to obtain the finalglobal_max_logits, and write it intometa.max_logitsin thecalc_attnreturn value for user access.
Experiments#
We benchmark FFA with max_logits enabled against the original implementation (without it) across full, causal, and varlen full/causal mask patterns for sequence lengths up to 16k.
As shown in the Fig. 70 below, throughput with max_logits remains close to the baseline: roughly 1%~2.5% overhead for full and causal masks, and about 2%~3.5% for the more challenging varlen full/causal cases, indicating a negligible runtime impact from computing and returning max_logits.
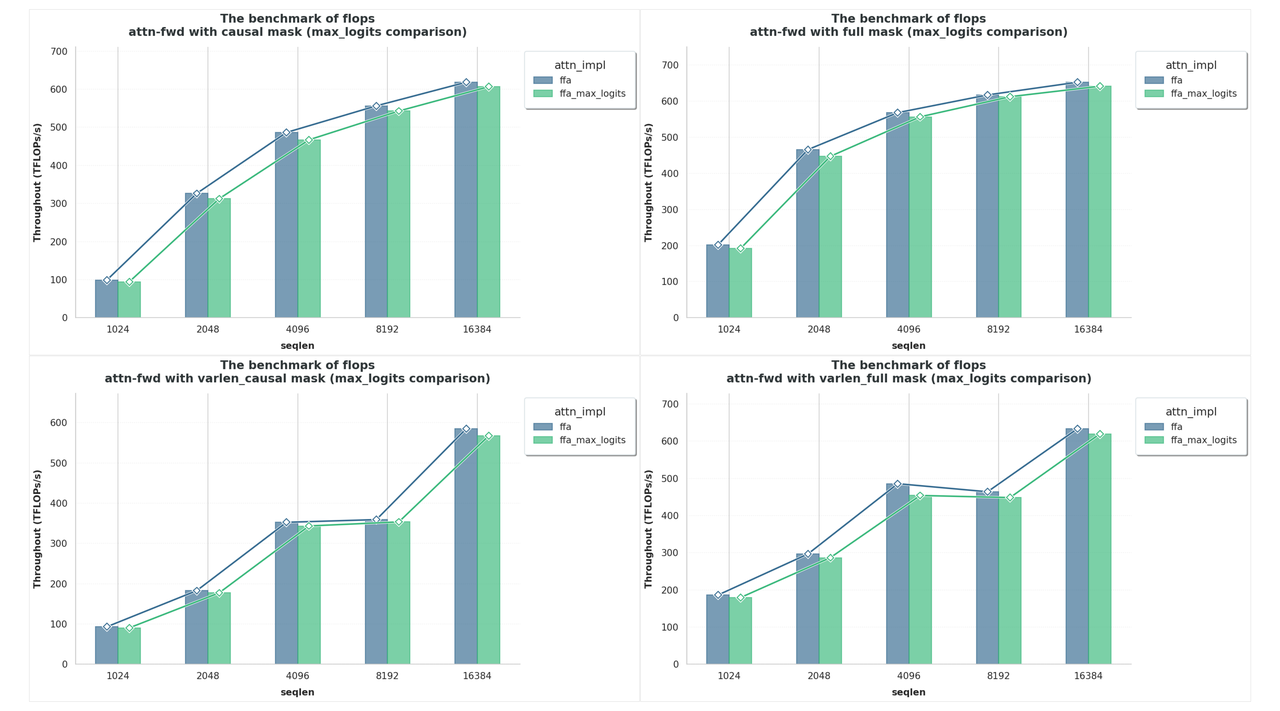
Fig. 70 Benchmark results of FFA with max_logits enabled against the original implementation (without it) across full, causal, and varlen full/causal mask patterns for sequence lengths up to 16k.#
Citation#
If you find MagiAttention useful in your research, please cite:
@misc{magiattention2025,
title={MagiAttention: A Distributed Attention Towards Linear Scalability for Ultra-Long Context, Heterogeneous Mask Training},
author={Zewei, Tao and Yunpeng, Huang},
year={2025},
howpublished={\url{https://github.com/SandAI-org/MagiAttention/}},
}
References#
Tri Dao. Flashattention-2: faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: an optimizer for hidden layers in neural networks. 2024. URL: https://kellerjordan.github.io/posts/muon/.
Diederik P. Kingma and Jimmy Ba. Adam: a method for stochastic optimization. 2017. URL: https://arxiv.org/abs/1412.6980, arXiv:1412.6980.
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is scalable for llm training. 2025. URL: https://arxiv.org/abs/2502.16982, arXiv:2502.16982.
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. 2019. URL: https://arxiv.org/abs/1711.05101, arXiv:1711.05101.
Kimi Team, Yifan Bai, Yiping Bao, Y. Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Chenxiao Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Yuyao Ge, Shangyi Geng, Qizheng Gu, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo, Xiaoru Hao, Tianhong He, Weiran He, Wenyang He, Yunjia He, Chao Hong, Hao Hu, Yangyang Hu, Zhenxing Hu, Weixiao Huang, Zhiqi Huang, Zihao Huang, Tao Jiang, Zhejun Jiang, Xinyi Jin, Yongsheng Kang, Guokun Lai, Cheng Li, Fang Li, Haoyang Li, Ming Li, Wentao Li, Yang Li, Yanhao Li, Yiwei Li, Zhaowei Li, Zheming Li, Hongzhan Lin, Xiaohan Lin, Zongyu Lin, Chengyin Liu, Chenyu Liu, Hongzhang Liu, Jingyuan Liu, Junqi Liu, Liang Liu, Shaowei Liu, T. Y. Liu, Tianwei Liu, Weizhou Liu, Yangyang Liu, Yibo Liu, Yiping Liu, Yue Liu, Zhengying Liu, Enzhe Lu, Haoyu Lu, Lijun Lu, Yashuo Luo, Shengling Ma, Xinyu Ma, Yingwei Ma, Shaoguang Mao, Jie Mei, Xin Men, Yibo Miao, Siyuan Pan, Yebo Peng, Ruoyu Qin, Zeyu Qin, Bowen Qu, Zeyu Shang, Lidong Shi, Shengyuan Shi, Feifan Song, Jianlin Su, Zhengyuan Su, Lin Sui, Xinjie Sun, Flood Sung, Yunpeng Tai, Heyi Tang, Jiawen Tao, Qifeng Teng, Chaoran Tian, Chensi Wang, Dinglu Wang, Feng Wang, Hailong Wang, Haiming Wang, Jianzhou Wang, Jiaxing Wang, Jinhong Wang, Shengjie Wang, Shuyi Wang, Si Wang, Xinyuan Wang, Yao Wang, Yejie Wang, Yiqin Wang, Yuxin Wang, Yuzhi Wang, Zhaoji Wang, Zhengtao Wang, Zhengtao Wang, Zhexu Wang, Chu Wei, Qianqian Wei, Haoning Wu, Wenhao Wu, Xingzhe Wu, Yuxin Wu, Chenjun Xiao, Jin Xie, Xiaotong Xie, Weimin Xiong, Boyu Xu, Jinjing Xu, L. H. Xu, Lin Xu, Suting Xu, Weixin Xu, Xinran Xu, Yangchuan Xu, Ziyao Xu, Jing Xu, Jing Xu, Junjie Yan, Yuzi Yan, Hao Yang, Xiaofei Yang, Yi Yang, Ying Yang, Zhen Yang, Zhilin Yang, Zonghan Yang, Haotian Yao, Xingcheng Yao, Wenjie Ye, Zhuorui Ye, Bohong Yin, Longhui Yu, Enming Yuan, Hongbang Yuan, Mengjie Yuan, Siyu Yuan, Haobing Zhan, Dehao Zhang, Hao Zhang, Wanlu Zhang, Xiaobin Zhang, Yadong Zhang, Yangkun Zhang, Yichi Zhang, Yizhi Zhang, Yongting Zhang, Yu Zhang, Yutao Zhang, Yutong Zhang, Zheng Zhang, Haotian Zhao, Yikai Zhao, Zijia Zhao, Huabin Zheng, Shaojie Zheng, Longguang Zhong, Jianren Zhou, Xinyu Zhou, Zaida Zhou, Jinguo Zhu, Zhen Zhu, Weiyu Zhuang, and Xinxing Zu. Kimi k2: open agentic intelligence. 2026. URL: https://arxiv.org/abs/2507.20534, arXiv:2507.20534.