Support Blackwell with FFA_FA4 Backend#
Introduction#
Before the release of MagiAttention-v1.1.0, MagiAttention had supported only the Hopper GPUs, since the attention kernel backend Flex-Flash-Attention (FFA) is built upon open-sourced Flash-Attention 3 (FA3) [Shah et al., 2024], tailored for SM90 compute capability.
To provide early support for the latest Blackwell GPUs, instead of natively extending the FFA kernels, which is the future plan to deliver utmost flexibility and performance potential, we have been actively collaborating with MINIMAX peers and NVIDIA team and implemented a temporary attention kernel backend named FFA_FA4, built upon a forked Flash-Attention 4 (FA4) and equipped with flexible mask support via an HSTU Function representation.
This allows us to quickly integrate Blackwell support into MagiAttention and provide users with the opportunity to leverage the enhanced SM100+ capabilities of Blackwell for their attention computations, while we continue to work on the native FFA extension for Blackwell in the background.
User Interface#
Installation#
Installing MagiAttention with FFA_FA4 currently requires additional steps. See the Installation Guide for details; we plan to streamline this process in the future.
Enabling#
To enable FFA_FA4 backend on Blackwell GPUs, users can simply set the environment variable export MAGI_ATTENTION_FA4_BACKEND=1.
Pre-Compilation#
Since FFA_FA4 relies on a forked version of Flash-Attention 4 based on Cute PythonDSL [Corporation, 2026], it requires JIT-compilation of the attention kernels for different mask patterns, thus we recommend you to pre-compile the common cases for FFA_FA4 kernels before production usage to avoid runtime JIT re-compilation overhead. See the Installation Guide for details.
Implementation#
HSTU Function Representation#
In FFA, we introduce a novel AttnSlice Representation of attention masks, which enables efficient kernel execution with distributable and flexible mask support. However, it requires a major modification, including AttnSlice-level Parallelism, upon FA3 kernels that are currently only available on Hopper, and cannot be easily and directly applied to FA4 kernels on Blackwell.
To provide early support for flexible masking on Blackwell, NVIDIA team and we introduce the HSTU Function representation, which allows us to handle various mask patterns without extensive changes to the underlying FA4 kernels.
Specifically, we represent the attention mask as a boolean matrix with the shape (seqlen_q, seqlen_k), where each row of shape (seqlen_k,) corresponds to a query token about which key tokens it can attend to. Then for \(i\)-th row, instead of directly storing the boolean values, we represent it as several segments of consecutive True values, and the \(j\)-th segment’s start / end token index formed as a \([start, end)\) token range, can be mapped by HSTU Function that takes coordinate \((i,2j-1)\) / \((i,2j)\) as input, where the \(0\)-th segment’s start token index is always 0 so can be omitted in the function representation.
Therefore, each row can be represented by the HSTU Function as follows:
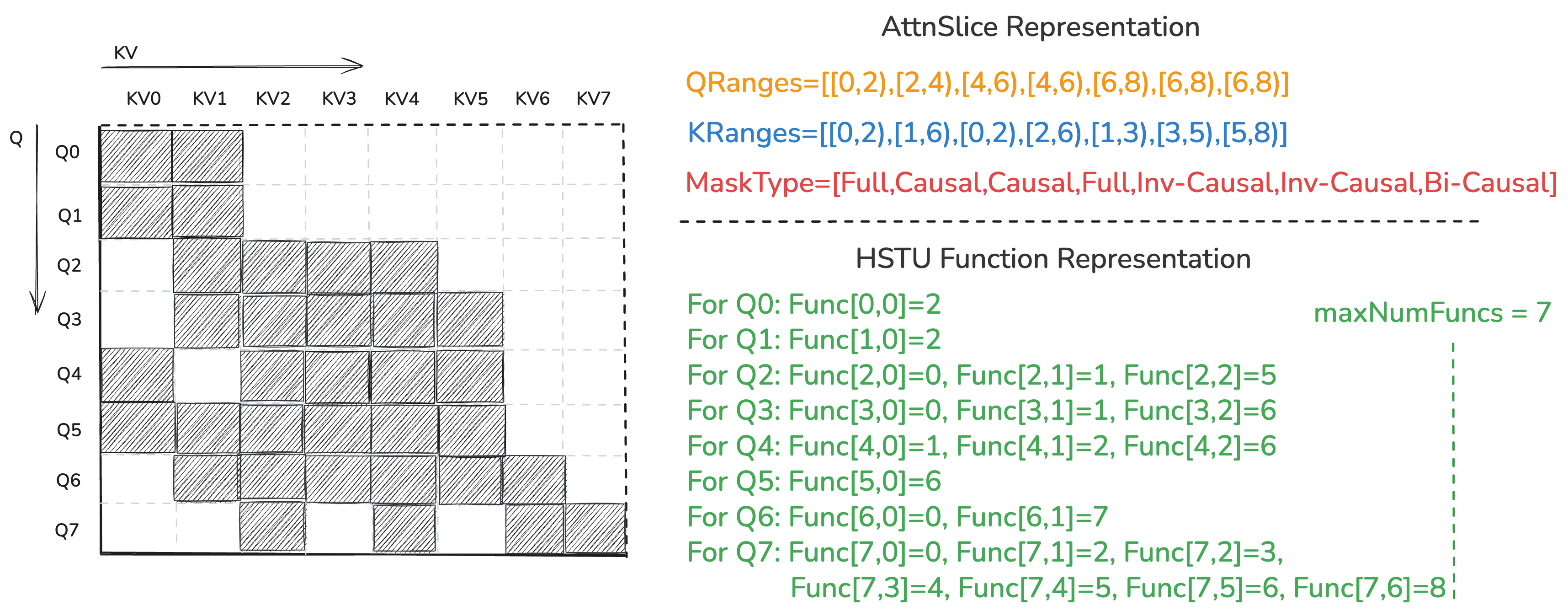
Fig. 65 Example of HSTU Function representation compared to AttnSlice representation for an irregular attention mask pattern.#
Flash-Attention 4 Modifications#
To fully leverage the HSTU Function for flexible masking on Blackwell, we implemented several critical modifications to the base FA4 kernels, focusing on block-level sparsity generation, memory efficiency, and low-level instruction optimization.
Efficient Block Sparsity Generation#
Since Flash-Attention operates on a block-wise computation by tiling the entire attention mask, we categorize each block into one of three states to skip unnecessary computations: Full (no masking needed), Partial (masking required), or Empty (completely masked and can be skipped).
While Flex-Attention in PyTorch provides a mechanism to generate block-sparse information, its naive implementation [PyTorch Contributors, n.d.] relies on intermediate tensors that materialize the complete attention mask, which easily results in OOM errors and introduces significant latency for long sequences. To address this, we developed a high-performance create_block_mask kernel that parses the HSTU Function directly [Chen et al., 2026].
This kernel includes both q2k (forward) and k2q (backward) implementations. In the forward pass, we employ a specific optimization: if an n-block is out-of-bounds only in the q direction, we treat it as a Full block. Since out-of-bound data does not affect the valid computation result and is not written back, this heuristic reduces the number of Partial blocks, thereby improving the throughput of the attention kernel.
CSR Compression for Sparsity Metadata#
The original FA4 sparsity metadata structure uses fixed-size tensors to store block indices, which scales poorly with sequence length and sparsity. Specifically, it stores full_block_cnt, full_block_idx, mask_block_cnt, and mask_block_idx. For highly sparse masks, the idx tensors (of shape [batch, head, m_block_num, n_block_num]) waste significant memory.
We refactored this into a Compressed Sparse Row (CSR) format, consisting of six components:
full_block_cnt/mask_block_cntfull_block_offset/mask_block_offsetfull_block_idx/mask_block_idx(compacted)
By using offsets to locate the valid n-block indices for each m-block, we only store the indices of non-empty blocks. This transition to CSR significantly reduces the memory footprint of metadata, allowing FFA_FA4 to scale to ultra-long contexts.
Instruction-Level Predication Optimization (R2P)#
In the softmax warp, the apply_mask stage can become a major bottleneck if implemented naively. Checking every token against \(n\_{func}\) boundaries introduces a massive amount of comparison instructions, causing the softmax latency to even exceed the execution time of the two forward MMAs.
To solve this, we optimized the masking logic using the R2P (Register-to-Predicate) technique in the forward pass. Instead of element-wise validity checks, we process 24 elements as a batch using an int32 bitmap. For each KV interval \([a, b)\), we construct the bitmap using bitwise XOR:
# XOR to generate mask for interval [a, b)
interval_mask = ((1 << b) - 1) ^ ((1 << a) - 1)
# OR to combine multiple intervals
combined_mask = combined_mask | interval_mask
The resulting combined_mask is then mapped to hardware predicates via the R2P instruction, which “scatters” the bits of a register into multiple predicate registers in a single cycle.
# R2P to batch set predicates
for i in cutlass.range_constexpr(min(24, ncol - s * 24)):
in_bound = cutlass.Boolean(combined_mask & (1 << i))
X[c] = X[c] if in_bound else -Float32.inf
Compared to the standard implementation, this approach drastically reduces the instruction count:
Standard: Requires approx. \(128 \times n\_{func}\)
ISETP.LEinstructions, 127UIADD3instructions, and \(128 \times (n\_{func}/2 + 1)\)SELinstructions per tile.R2P Optimization: Eliminates most comparison and coordinate addition instructions, reducing
SELcount to 128 and bitmask logic to \(O(\lceil 128/24 \rceil \times n\_{func}/2)\).
This ensures that the flex-mask overhead no longer bottlenecks the operator pipeline, even as \(n\_{func}\) increases.
Runtime and Kernel Launch Optimization#
Since FA4 utilizes the Cute PythonDSL [Corporation, 2026], kernel launching can be expensive due to metadata conversion. We integrated the tvm_ffi library to streamline the interface between PyTorch and the DSL [Corporation, 2026].
For each unique compile_key, we perform an explicit torch.Tensor to DSL.Tensor conversion only during the first call. Subsequent executions bypass repeated from_dlpack calls, significantly reducing host-side overhead during the launch phase.
Integration into MagiAttention#
To bridge the gap between MagiAttention’s native AttnSlice Representation and the HSTU Function required by FFA_FA4, we developed the magi_to_hstu CUDA kernel [Yang, 2026].
In this kernel, each CUDA thread processes a single query token (q_idx) through two main steps:
Interval Collection: The thread iterates through all
AttnSlices. Ifq_idxfalls within a slice’s query range, it calculates the corresponding KV interval boundaries. For causal-like masks (e.g., trapezoidal or diamond patterns), we use efficient ternary expressions to determine the offsets based on themask_type:// Calculate boundaries for each q token int k_interval_start = k_start + ((mask_type & 2) ? (q_idx - q_start) : 0); int k_interval_end = k_end - ((mask_type & 1) ? (q_end - q_idx - 1) : 0);
mask type
offset_start
offset_end
description
Full0
0
No cropping; the KV interval remains constant for all \(q\) tokens in the slice.
Causal0
q_end-q_idx- 1Right-side shrinkage; tokens at the beginning of the \(q\) range see fewer \(k\) tokens.
Inverse-Causalq_idx-q_start0
Left-side shrinkage; tokens at the end of the \(q\) range see fewer \(k\) tokens.
Bi-Causalq_idx-q_startq_end-q_idx- 1Shrinkage from both sides; forms a diamond-shaped mask
Sorting and Merging: After collecting all KV intervals for the current
q_idx, we perform an in-place insertion sort based on the left boundaries. This allows for efficient merging of overlapping or consecutive intervals, which are then output in the format required by theHSTU Function.
It is noteworthy that FFA_FA4 takes the maximum number of segments (\(n\_{func}\)) as a template parameter. To maximize performance, magi_to_hstu dynamically calculates the minimum required \(n\_{func}\) for the current mask pattern, allowing the system to dispatch the most efficient kernel version.
However, this may trigger JIT compilation for unseen \(n\_{func}\) values, which is why we recommend pre-compilation for production environments.
Note
While FFA_FA4 provides a pathway to support flexible masking on Blackwell, it is a temporary solution. The long-term plan is to extend the native FFA kernels to Blackwell, which will unlock the full potential of the architecture and provide even better performance and flexibility under more complex scenarios like (distributed) sparse attention.
Experiments#
We present representative kernel-level/distributed-level benchmarks below for the most commonly used varlen causal mask on B200 GPUs,highlighting MagiAttention’s performance and scalability with the FFA_FA4 backend versus state-of-the-art context-parallel (CP) strategies and leading attention kernel baselines.
For detailed benchmark settings and more benchmarking results, see the separate blog post.
Note
For FA4 kernel baseline, we don’t report the backward performance since it currently lacks robust support for varlen masks, especially on stable version of 2.8.3, which is also the reason why we use cuDNN as the kernel backend for most of the CP baselines.
Kernel Level#
Fig. 66 (a) Forward Pass#
Fig. 67 (b) Backward Pass#
Benchmarking FFA_FA4’s performance and flexibility against baselines on B200 for the varlen causal mask.
Distributed Level#
Fig. 68 (a) Forward Pass#
Fig. 69 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on B200 for the varlen causal mask.
Citation#
If you find MagiAttention useful in your research, please cite:
@misc{magiattention2025,
title={MagiAttention: A Distributed Attention Towards Linear Scalability for Ultra-Long Context, Heterogeneous Mask Training},
author={Zewei, Tao and Yunpeng, Huang},
year={2025},
howpublished={\url{https://github.com/SandAI-org/MagiAttention/}},
}
References#
Jerry Chen, Yujia Liu, and Yufeng Yang. Flashattention: create block mask utility for magi attn (blackwell support). GitHub Repository, 2026. URL: demonatic/flash-attention.
NVIDIA Corporation. Cutlass: compile with tvm ffi (cute dsl general). NVIDIA Official Documentation, 2026. URL: https://docs.nvidia.com/cutlass/latest/media/docs/pythonDSL/cute_dsl_general/compile_with_tvm_ffi.html.
NVIDIA Corporation. Cutlass: python dsl overview documentation. NVIDIA Official Documentation, 2026. URL: https://docs.nvidia.com/cutlass/latest/media/docs/pythonDSL/overview.html.
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: fast and accurate attention with asynchrony and low-precision. 2024. URL: https://arxiv.org/abs/2407.08608, arXiv:2407.08608.
Yufeng Yang. Flashattention: magi attn to hstu conversion utility (blackwell support). GitHub Repository, 2026. URL: demonatic/flash-attention.
PyTorch Contributors. Flexattention: create_block_mask api documentation. https://docs.pytorch.org/docs/stable/nn.attention.flex_attention.html#torch.nn.attention.flex_attention.create_block_mask.