Long-Context Attention Benchmark#
From Kernel Efficiency to Distributed Scalability
To evaluate the performance and flexibility of Flex-Flash-Attention (FFA) kernels and to validate the distributed scalability of MagiAttention for ultra-long, heterogeneous-mask training, we benchmark throughput on modern GPUs (e.g., Hopper and Blackwell) for both kernels and distributed attention modules in forward and backward passes across diverse mask patterns (standard and irregular), against state-of-the-art kernel- and distributed-level baselines.
Benchmark Settings#
Common Configurations#
To focus on the impact of sequence length and mask pattern, we fix other data and model configurations using common training settings as shown in the table below.
settings |
value |
|---|---|
attention type |
self-attention where |
batch size (b) |
1 |
number of heads (nh) |
nhq:nhk:nhv = 64:8:8 (GQA) |
head dimension (hd) |
128 |
dtype |
|
window size |
1024 (for sliding window masks only) |
Throughput Metrics#
Throughput is measured in \(\texttt{TFLOPs/s}\) for kernel-level benchmarks and \(\texttt{TFLOPs/s/GPU}\) for distributed benchmarks, calculated based on the total number of floating-point operations (\(\texttt{FLOPs}\)) involved in the attention computation, for both forward and backward passes respectively.
The \(\texttt{FLOPs}\) for each \(\mathrm{AttnSlice}\) are computed using the formula below, and the total \(\texttt{FLOPs}\) is the summation of all \(\mathrm{AttnSlice}\):
And the throughputs are calculated as follows:
Data Distribution and Sampling#
To reflect real-world long-context training, we extract the sequence-length distribution from a representative training dataset and use it to construct variable-length inputs for both kernel- and distributed-level experiments (see Fig. 19).
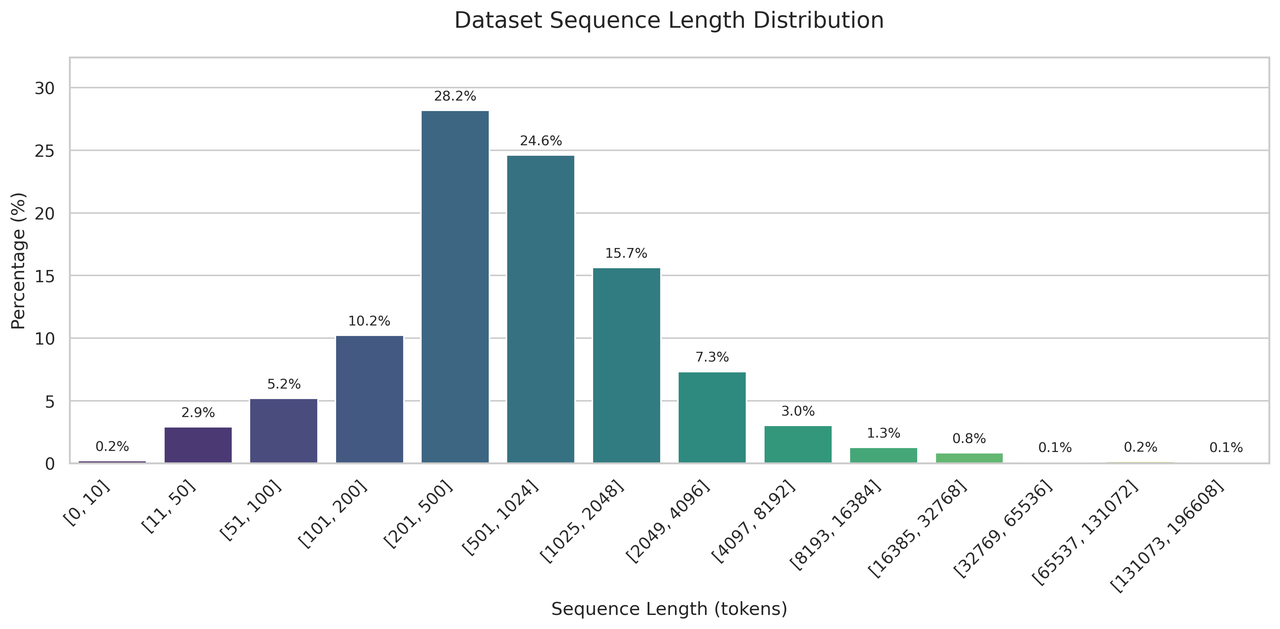
Fig. 19 Distribution of sequence lengths extracted from a real-world dataset, which is used to sample and construct the variable-length data for both kernel-level and distributed-level experiments.#
We shuffle the dataset, sequentially pack samples into data packs, then reshuffle those packs to form the final sampling set, where we will fetch a portion of packs for experiments using varlen mask patterns. This preserves the original token-length distribution so the probability of tokens from long and short samples within each pack matches the dataset.
To avoid the sampled variable-length data from degenerating into pure full/causal masks to affect the evaluation, we limit each sample’s length at most \(\frac{1}{4}\) of the total sequence length (e.g., no sample exceeds 16K when measuring with a 64K total sequence length).
Kernel Baselines#
On Hopper, we evaluate our FFA kernel against widely used PyTorch’s fused SDPA [PyTorch, n.d.], Flash Attention 2 (FA2) [Dao, 2023], Flash Attention 3 (FA3) [Shah et al., 2024], NVIDIA’s cuDNN fused attention kernel [NVIDIA, 2024] from TransformerEngine, as well as PyTorch’s new FlexAttention [Dong et al., 2024] and Baidu’s FlashMask [Wang et al., 2025] for baselines on flexible masks.
On Blackwell, we instead evaluate our FFA_FA4 kernel against the same baselines, substituting FA2 and FA3 with Flash Attention 4 (FA4) [Dao et al., 2025], since both FFA and FA3 are tailored for Hopper and FA2 does not optimize for SM90+ architectures. And we don’t report the backward performance for FA4 since it currently lacks robust support for varlen masks, especially on stable version of 2.8.3.
Distributed Baselines#
We evaluate MagiAttention against state-of-the-art distributed attention mechanisms integrated into Megatron-LM as context-parallel (CP) backends, including Ulysess [Jacobs et al., 2023], Ring P2P [Liu et al., 2023], Ring AllGather [Grattafiori et al., 2024], USP [Fang and Zhao, 2024], LoongTrain [Gu et al., 2024], and Megatron HybridCP [NVIDIA, 2025]. Many of these are discussed in the Related Work section of the main MagiAttention blog post.
On Hopper, all baselines use the FA3 kernel as the attention backend to ensure a fair comparison with our FFA kernel.
On Blackwell, since FA3 targets Hopper and FA4 currently lacks robust backward support for varlen masks on stable version of 2.8.3, baselines use the cuDNN kernel while we use our FFA_FA4 backend. Additionally, Megatron HybridCP (which requires FA3) is omitted from Blackwell evaluations.
Kernel Level#
For kernel-level benchmarking, we evaluate the kernels across 5 common mask patterns including full, causal, varlen full, varlen causal and sliding window causal with one irregular varlen block causal mask used in Magi-1, to assess performance and flexibility, with the total sequence length varying from 1K,2K,4K,..., up to 64K for both forward and backward passes.
Results are reported in the following figures, while the legend-name mapping is described below:
legend |
name |
|---|---|
ffa |
|
fa2 / fa3 / fa4 |
|
cudnn |
NVIDIA |
sdpa |
PyTorch’s |
flex |
PyTorch’s |
flash_mask |
Baidu’s |
Note
The \(\mathbf{X}\) symbol denotes attention kernels unsupported in that configuration due to kernel limitations or error raised (e.g., Cuda Out of Memory).
For H100#
Full Mask#
Fig. 20 (a) Forward Pass#
Fig. 21 (b) Backward Pass#
Benchmarking FFA’s performance and flexibility against baselines on H100 for the full mask.
Causal Mask#
Fig. 22 (a) Forward Pass#
Fig. 23 (b) Backward Pass#
Benchmarking FFA’s performance and flexibility against baselines on H100 for the causal mask.
Varlen Full Mask#
Fig. 24 (a) Forward Pass#
Fig. 25 (b) Backward Pass#
Benchmarking FFA’s performance and flexibility against baselines on H100 for the varlen full mask.
Varlen Causal Mask#
Fig. 26 (a) Forward Pass#
Fig. 27 (b) Backward Pass#
Benchmarking FFA’s performance and flexibility against baselines on H100 for the varlen causal mask.
Sliding Window Causal Mask#
Fig. 28 (a) Forward Pass#
Fig. 29 (b) Backward Pass#
Benchmarking FFA’s performance and flexibility against baselines on H100 for the sliding window causal mask.
Varlen Block Causal Mask 🔥#
Fig. 30 (a) Forward Pass#
Fig. 31 (b) Backward Pass#
Benchmarking FFA’s performance and flexibility against baselines on H100 for the varlen block causal mask.
For B200#
Full Mask#
Fig. 32 (a) Forward Pass#
Fig. 33 (b) Backward Pass#
Benchmarking FFA_FA4’s performance and flexibility against baselines on B200 for the full mask.
Causal Mask#
Fig. 34 (a) Forward Pass#
Fig. 35 (b) Backward Pass#
Benchmarking FFA_FA4’s performance and flexibility against baselines on B200 for the causal mask.
Varlen Full Mask#
Fig. 36 (a) Forward Pass#
Fig. 37 (b) Backward Pass#
Benchmarking FFA_FA4’s performance and flexibility against baselines on B200 for the varlen full mask.
Varlen Causal Mask#
Fig. 38 (a) Forward Pass#
Fig. 39 (b) Backward Pass#
Benchmarking FFA_FA4’s performance and flexibility against baselines on B200 for the varlen causal mask.
Sliding Window Causal Mask#
Fig. 40 (a) Forward Pass#
Fig. 41 (b) Backward Pass#
Benchmarking FFA_FA4’s performance and flexibility against baselines on B200 for the sliding window causal mask.
Varlen Block Causal Mask 🔥#
Fig. 42 (a) Forward Pass#
Fig. 43 (b) Backward Pass#
Benchmarking FFA_FA4’s performance and flexibility against baselines on B200 for the varlen block causal mask.
Distributed Level#
For distributed-level benchmarking, we evaluate the CP strategies across 4 common mask patterns including full, causal, varlen full and varlen causal, to assess performance and scalability, with the cp_size scaling from 8 up to 64 for both forward and backward passes.
As for the total sequence length, we scale it linearly together with cp_size and fix the per-device sequence length to reflect the common training configuration w.r.t. the GPU memory capacity, e.g. 8K for H100 and 16K for B200.
Results are reported in the following figures, while the legend-name mapping is described below:
legend |
name |
|---|---|
magi_attn-a2av |
|
magi_attn-native |
|
ulysses |
|
ring_p2p |
|
ring_allgather |
|
usp |
|
loongtrain |
|
hybrid_dcp |
Megatron |
Note
For MagiAttention, we include two instances with different backends of group collectives: one using the original AlltoAll-v-based implementation and the other using native kernel based on DeepEP [Zhao et al., 2025], to demonstrate the significant gain from our new native backend.
Warning
We’ve applied some experimental features on MagiAttention to further optimize the performance on benchmarking, which may not be enabled by default or fully ready for production use yet.
Therefore, the benchmarking results of MagiAttention in this section are intended to demonstrate the potential performance and scalability of our design, while the actual performance in production may vary and require to be tuned specifically.
We will continue to optimize and stabilize those features and ease the adoption in production, and very welcome users to try out those features and provide feedback to us.
For H100#
Full Mask#
Fig. 44 (a) Forward Pass#
Fig. 45 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on H100 for the full mask.
Causal Mask#
Fig. 46 (a) Forward Pass#
Fig. 47 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on H100 for the causal mask.
Varlen Full Mask 🔥#
Fig. 48 (a) Forward Pass#
Fig. 49 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on H100 for the varlen full mask.
Varlen Causal Mask 🔥#
Fig. 50 (a) Forward Pass#
Fig. 51 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on H100 for the varlen causal mask.
For B200#
Full Mask#
Fig. 52 (a) Forward Pass#
Fig. 53 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on B200 for the full mask.
Causal Mask#
Fig. 54 (a) Forward Pass#
Fig. 55 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on B200 for the causal mask.
Varlen Full Mask 🔥#
Fig. 56 (a) Forward Pass#
Fig. 57 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on B200 for the varlen full mask.
Varlen Causal Mask 🔥#
Fig. 58 (a) Forward Pass#
Fig. 59 (b) Backward Pass#
Benchmarking MagiAttention’s performance and scalability against baselines on B200 for the varlen causal mask.
Citation#
If you find MagiAttention useful in your research, please cite:
@misc{magiattention2025,
title={MagiAttention: A Distributed Attention Towards Linear Scalability for Ultra-Long Context, Heterogeneous Mask Training},
author={Zewei, Tao and Yunpeng, Huang},
year={2025},
howpublished={\url{https://github.com/SandAI-org/MagiAttention/}},
}
References#
Tri Dao. Flashattention-2: faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
Tri Dao, Guessous Driss, and Tsang Henry. Flashattention cute module [software documentation]. GitHub Repository README, 2025. URL: Dao-AILab/flash-attention.
Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang, and Horace He. Flex attention: a programming model for generating optimized attention kernels. 2024. URL: https://arxiv.org/abs/2412.05496, arXiv:2412.05496.
Jiarui Fang and Shangchun Zhao. Usp: a unified sequence parallelism approach for long context generative ai. 2024. URL: https://arxiv.org/abs/2405.07719, arXiv:2405.07719.
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Bethany Biron, Binh Tang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller, Christophe Touret, Chunyang Wu, Corinne Wong, Cristian Canton Ferrer, Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, Danny Wyatt, David Esiobu, Dhruv Choudhary, Dhruv Mahajan, Diego Garcia-Olano, Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy, Elina Lobanova, Emily Dinan, Eric Michael Smith, Filip Radenovic, Francisco Guzmán, Frank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Govind Thattai, Graeme Nail, Gregoire Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Korevaar, Hu Xu, Hugo Touvron, Iliyan Zarov, Imanol Arrieta Ibarra, Isabel Kloumann, Ishan Misra, Ivan Evtimov, Jack Zhang, Jade Copet, Jaewon Lee, Jan Geffert, Jana Vranes, Jason Park, Jay Mahadeokar, Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jianyu Huang, Jiawen Liu, Jie Wang, Jiecao Yu, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan Vasuden Alwala, Karthik Prasad, Kartikeya Upasani, Kate Plawiak, Ke Li, Kenneth Heafield, Kevin Stone, Khalid El-Arini, Krithika Iyer, Kshitiz Malik, Kuenley Chiu, Kunal Bhalla, Kushal Lakhotia, Lauren Rantala-Yeary, Laurens van der Maaten, Lawrence Chen, Liang Tan, Liz Jenkins, Louis Martin, Lovish Madaan, Lubo Malo, Lukas Blecher, Lukas Landzaat, Luke de Oliveira, Madeline Muzzi, Mahesh Pasupuleti, Mannat Singh, Manohar Paluri, Marcin Kardas, Maria Tsimpoukelli, Mathew Oldham, Mathieu Rita, Maya Pavlova, Melanie Kambadur, Mike Lewis, Min Si, Mitesh Kumar Singh, Mona Hassan, Naman Goyal, Narjes Torabi, Nikolay Bashlykov, Nikolay Bogoychev, Niladri Chatterji, Ning Zhang, Olivier Duchenne, Onur Çelebi, Patrick Alrassy, Pengchuan Zhang, Pengwei Li, Petar Vasic, Peter Weng, Prajjwal Bhargava, Pratik Dubal, Praveen Krishnan, Punit Singh Koura, Puxin Xu, Qing He, Qingxiao Dong, Ragavan Srinivasan, Raj Ganapathy, Ramon Calderer, Ricardo Silveira Cabral, Robert Stojnic, Roberta Raileanu, Rohan Maheswari, Rohit Girdhar, Rohit Patel, Romain Sauvestre, Ronnie Polidoro, Roshan Sumbaly, Ross Taylor, Ruan Silva, Rui Hou, Rui Wang, Saghar Hosseini, Sahana Chennabasappa, Sanjay Singh, Sean Bell, Seohyun Sonia Kim, Sergey Edunov, Shaoliang Nie, Sharan Narang, Sharath Raparthy, Sheng Shen, Shengye Wan, Shruti Bhosale, Shun Zhang, Simon Vandenhende, Soumya Batra, Spencer Whitman, Sten Sootla, Stephane Collot, Suchin Gururangan, Sydney Borodinsky, Tamar Herman, Tara Fowler, Tarek Sheasha, Thomas Georgiou, Thomas Scialom, Tobias Speckbacher, Todor Mihaylov, Tong Xiao, Ujjwal Karn, Vedanuj Goswami, Vibhor Gupta, Vignesh Ramanathan, Viktor Kerkez, Vincent Gonguet, Virginie Do, Vish Vogeti, Vítor Albiero, Vladan Petrovic, Weiwei Chu, Wenhan Xiong, Wenyin Fu, Whitney Meers, Xavier Martinet, Xiaodong Wang, Xiaofang Wang, Xiaoqing Ellen Tan, Xide Xia, Xinfeng Xie, Xuchao Jia, Xuewei Wang, Yaelle Goldschlag, Yashesh Gaur, Yasmine Babaei, Yi Wen, Yiwen Song, Yuchen Zhang, Yue Li, Yuning Mao, Zacharie Delpierre Coudert, Zheng Yan, Zhengxing Chen, Zoe Papakipos, Aaditya Singh, Aayushi Srivastava, Abha Jain, Adam Kelsey, Adam Shajnfeld, Adithya Gangidi, Adolfo Victoria, Ahuva Goldstand, Ajay Menon, Ajay Sharma, Alex Boesenberg, Alexei Baevski, Allie Feinstein, Amanda Kallet, Amit Sangani, Amos Teo, Anam Yunus, Andrei Lupu, Andres Alvarado, Andrew Caples, Andrew Gu, Andrew Ho, Andrew Poulton, Andrew Ryan, Ankit Ramchandani, Annie Dong, Annie Franco, Anuj Goyal, Aparajita Saraf, Arkabandhu Chowdhury, Ashley Gabriel, Ashwin Bharambe, Assaf Eisenman, Azadeh Yazdan, Beau James, Ben Maurer, Benjamin Leonhardi, Bernie Huang, Beth Loyd, Beto De Paola, Bhargavi Paranjape, Bing Liu, Bo Wu, Boyu Ni, Braden Hancock, Bram Wasti, Brandon Spence, Brani Stojkovic, Brian Gamido, Britt Montalvo, Carl Parker, Carly Burton, Catalina Mejia, Ce Liu, Changhan Wang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tindal, Christoph Feichtenhofer, Cynthia Gao, Damon Civin, Dana Beaty, Daniel Kreymer, Daniel Li, David Adkins, David Xu, Davide Testuggine, Delia David, Devi Parikh, Diana Liskovich, Didem Foss, Dingkang Wang, Duc Le, Dustin Holland, Edward Dowling, Eissa Jamil, Elaine Montgomery, Eleonora Presani, Emily Hahn, Emily Wood, Eric-Tuan Le, Erik Brinkman, Esteban Arcaute, Evan Dunbar, Evan Smothers, Fei Sun, Felix Kreuk, Feng Tian, Filippos Kokkinos, Firat Ozgenel, Francesco Caggioni, Frank Kanayet, Frank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer, Georgia Swee, Gil Halpern, Grant Herman, Grigory Sizov, Guangyi, Zhang, Guna Lakshminarayanan, Hakan Inan, Hamid Shojanazeri, Han Zou, Hannah Wang, Hanwen Zha, Haroun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Hongyuan Zhan, Ibrahim Damlaj, Igor Molybog, Igor Tufanov, Ilias Leontiadis, Irina-Elena Veliche, Itai Gat, Jake Weissman, James Geboski, James Kohli, Janice Lam, Japhet Asher, Jean-Baptiste Gaya, Jeff Marcus, Jeff Tang, Jennifer Chan, Jenny Zhen, Jeremy Reizenstein, Jeremy Teboul, Jessica Zhong, Jian Jin, Jingyi Yang, Joe Cummings, Jon Carvill, Jon Shepard, Jonathan McPhie, Jonathan Torres, Josh Ginsburg, Junjie Wang, Kai Wu, Kam Hou U, Karan Saxena, Kartikay Khandelwal, Katayoun Zand, Kathy Matosich, Kaushik Veeraraghavan, Kelly Michelena, Keqian Li, Kiran Jagadeesh, Kun Huang, Kunal Chawla, Kyle Huang, Lailin Chen, Lakshya Garg, Lavender A, Leandro Silva, Lee Bell, Lei Zhang, Liangpeng Guo, Licheng Yu, Liron Moshkovich, Luca Wehrstedt, Madian Khabsa, Manav Avalani, Manish Bhatt, Martynas Mankus, Matan Hasson, Matthew Lennie, Matthias Reso, Maxim Groshev, Maxim Naumov, Maya Lathi, Meghan Keneally, Miao Liu, Michael L. Seltzer, Michal Valko, Michelle Restrepo, Mihir Patel, Mik Vyatskov, Mikayel Samvelyan, Mike Clark, Mike Macey, Mike Wang, Miquel Jubert Hermoso, Mo Metanat, Mohammad Rastegari, Munish Bansal, Nandhini Santhanam, Natascha Parks, Natasha White, Navyata Bawa, Nayan Singhal, Nick Egebo, Nicolas Usunier, Nikhil Mehta, Nikolay Pavlovich Laptev, Ning Dong, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar, Ozlem Kalinli, Parkin Kent, Parth Parekh, Paul Saab, Pavan Balaji, Pedro Rittner, Philip Bontrager, Pierre Roux, Piotr Dollar, Polina Zvyagina, Prashant Ratanchandani, Pritish Yuvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Rafi Ayub, Raghotham Murthy, Raghu Nayani, Rahul Mitra, Rangaprabhu Parthasarathy, Raymond Li, Rebekkah Hogan, Robin Battey, Rocky Wang, Russ Howes, Ruty Rinott, Sachin Mehta, Sachin Siby, Sai Jayesh Bondu, Samyak Datta, Sara Chugh, Sara Hunt, Sargun Dhillon, Sasha Sidorov, Satadru Pan, Saurabh Mahajan, Saurabh Verma, Seiji Yamamoto, Sharadh Ramaswamy, Shaun Lindsay, Shaun Lindsay, Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shishir Patil, Shiva Shankar, Shuqiang Zhang, Shuqiang Zhang, Sinong Wang, Sneha Agarwal, Soji Sajuyigbe, Soumith Chintala, Stephanie Max, Stephen Chen, Steve Kehoe, Steve Satterfield, Sudarshan Govindaprasad, Sumit Gupta, Summer Deng, Sungmin Cho, Sunny Virk, Suraj Subramanian, Sy Choudhury, Sydney Goldman, Tal Remez, Tamar Glaser, Tamara Best, Thilo Koehler, Thomas Robinson, Tianhe Li, Tianjun Zhang, Tim Matthews, Timothy Chou, Tzook Shaked, Varun Vontimitta, Victoria Ajayi, Victoria Montanez, Vijai Mohan, Vinay Satish Kumar, Vishal Mangla, Vlad Ionescu, Vlad Poenaru, Vlad Tiberiu Mihailescu, Vladimir Ivanov, Wei Li, Wenchen Wang, Wenwen Jiang, Wes Bouaziz, Will Constable, Xiaocheng Tang, Xiaojian Wu, Xiaolan Wang, Xilun Wu, Xinbo Gao, Yaniv Kleinman, Yanjun Chen, Ye Hu, Ye Jia, Ye Qi, Yenda Li, Yilin Zhang, Ying Zhang, Yossi Adi, Youngjin Nam, Yu, Wang, Yu Zhao, Yuchen Hao, Yundi Qian, Yunlu Li, Yuzi He, Zach Rait, Zachary DeVito, Zef Rosnbrick, Zhaoduo Wen, Zhenyu Yang, Zhiwei Zhao, and Zhiyu Ma. The llama 3 herd of models. 2024. URL: https://arxiv.org/abs/2407.21783, arXiv:2407.21783.
Diandian Gu, Peng Sun, Qinghao Hu, Ting Huang, Xun Chen, Yingtong Xiong, Guoteng Wang, Qiaoling Chen, Shangchun Zhao, Jiarui Fang, Yonggang Wen, Tianwei Zhang, Xin Jin, and Xuanzhe Liu. Loongtrain: efficient training of long-sequence llms with head-context parallelism. 2024. URL: https://arxiv.org/abs/2406.18485, arXiv:2406.18485.
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: system optimizations for enabling training of extreme long sequence transformer models. arXiv preprint arXiv:2309.14509, 2023. URL: https://arxiv.org/pdf/2309.14509.
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context. arXiv preprint arXiv:2310.01889, 2023.
NVIDIA. Accelerating transformers with nvidia cudnn 9. https://developer.nvidia.com/blog/accelerating-transformers-with-nvidia-cudnn-9/, 2024. Accessed: 2024-12-12.
PyTorch. Torch.nn.functional.scaled_dot_product_attention - pytorch 2.6 documentation. https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html.
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: fast and accurate attention with asynchrony and low-precision. 2024. URL: https://arxiv.org/abs/2407.08608, arXiv:2407.08608.
Guoxia Wang, Jinle Zeng, Xiyuan Xiao, Siming Wu, Jiabin Yang, Lujing Zheng, Zeyu Chen, Jiang Bian, Dianhai Yu, and Haifeng Wang. Flashmask: efficient and rich mask extension of flashattention. 2025. URL: https://arxiv.org/abs/2410.01359, arXiv:2410.01359.
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. Deepep: an efficient expert-parallel communication library. deepseek-ai/DeepEP, 2025.
NVIDIA. Megatron-lm pull request #2054. NVIDIA/Megatron-LM#2054, December 2025.